
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- kisa #보안관제
- 인프라 활용을 위한 파이썬
- Case Study
- 클라우드 기반
- Foxyproxy#install#setting#firefox
- 29기
- 클라우드 보안 기반
- 루키즈
- 애플리케이션 보안 기술
- 모듈프로젝트
- 모의침투
- Kali#Linux#Brute#Force#Attack#Test#DVWA#Hacking#Low#무차별#대입#공격#해킹
- rocky linux#siem#project#threat detection#soc#onpremise#ids#python#csv#pipeline#kali linux#DVWA#security monitoring
- DVWA#Brute#Force#Attack#Test#Kali#Linux#Medium#Level#sleep
- 개인정보보호
- 클라우드 보안 기술
- sk shieldus
- DVWA#INSTALL#github#security#kali#linux
- 시스템-네트워크 보안 기술
- #루키즈
- AI #취업
- 기술 특강 및 OT
- Kali#Linux#KALI#LINUX#INSTALL#github#설치
- CERT
- 보고서
- VMWARE#INSTALL#설치
- 클라우드기반 보안 시스템 구축/운영 실무
- 모듈 프로젝트
- sk 쉴더스 루키즈
- 쉴더스
- Today
- Total
이것저것
[SK shieldus Rookies 29기] 32일차 본문
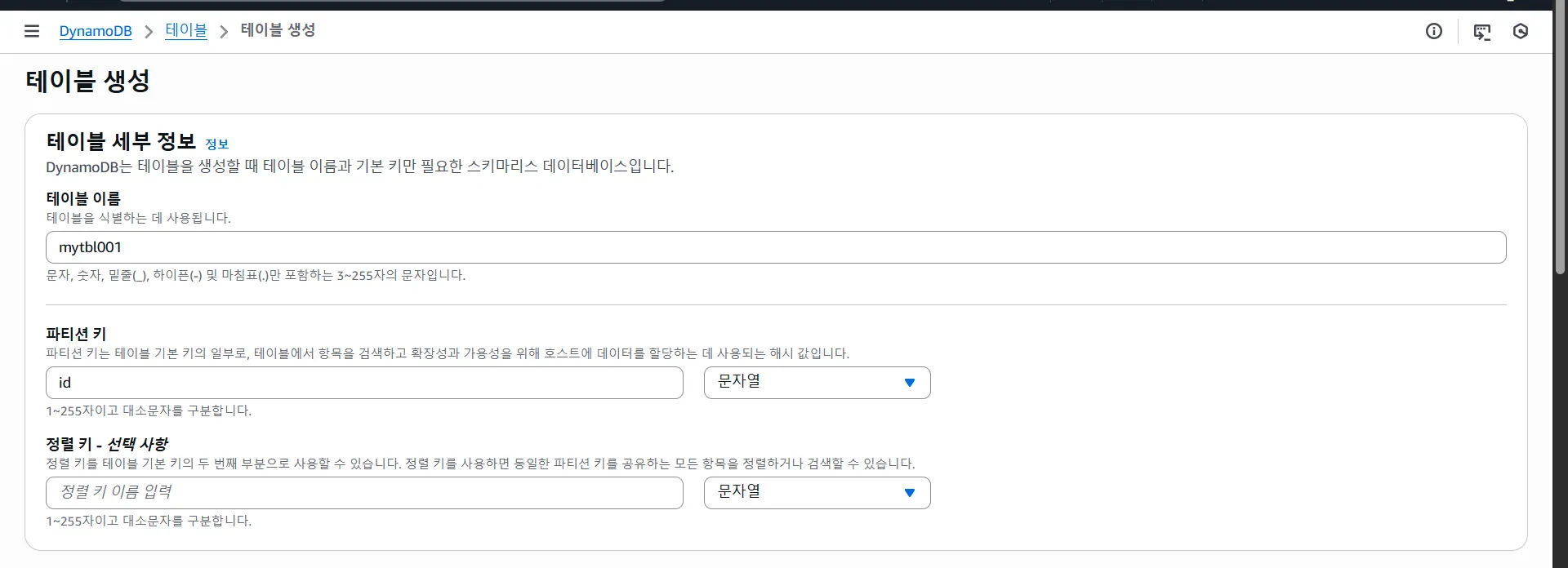
7.4 Amazon DynamoDB (NoSQL 키-값 DB)
DynamoDB란?
완전 관리형 NoSQL 데이터베이스
SQL 쿼리 없이, 키(Key)로 값(Value)을 매우 빠르게 가져오는 DB
예:
사용자_ID (키) → 사용자 정보 (값)
123 → {"name": "Alice", "age": 30, "city": "Seoul"}
456 → {"name": "Bob", "age": 25, "city": "Seoul"}RDS vs DynamoDB 비교
| 항목 | RDS (관계형) | DynamoDB (NoSQL) |
|---|---|---|
| 데이터 모델 | 테이블 + 행/열 | 파티션 키 + 속성 |
| 스키마 | 고정 (미리 정의) | 유연 (즉흥적) |
| 쿼리 | SQL (복잡한 조인) | 키로 직접 검색 |
| 확장성 | 수직 확장 (인스턴스 크기 ↑) | 수평 확장 (자동) |
| 속도 | 중간~빠름 | 초고속 (밀리초) |
| 트랜잭션 | ACID 지원 | 제한적 지원 |
| 비용 | 고정 (시간당) | 사용량 기반 (매우 저렴) |
| 사용 사례 | 전자상거래, ERP | 실시간 앱, 세션, 순위표 |
DynamoDB의 핵심 개념
1. 파티션 키 (Partition Key)
DynamoDB에서 데이터를 구분하는 "주키(Primary Key)"
예:
User 테이블:
├─ 파티션 키: UserID
└─ 데이터:
UserID: 123 → {name: Alice, email: alice@example.com}
UserID: 456 → {name: Bob, email: bob@example.com}파티션 키 값이 같으면 같은 항목, 파티션 키는 반드시 고유해야 함
2. 정렬 키 (Sort Key)
선택사항: 파티션 키로만 구분 안 될 때 추가
예:
OrderHistory 테이블:
├─ 파티션 키: UserID
├─ 정렬 키: OrderDate
└─ 데이터:
UserID: 123, OrderDate: 2025-01-15 → {amount: 50000}
UserID: 123, OrderDate: 2025-01-20 → {amount: 75000}
UserID: 456, OrderDate: 2025-01-18 → {amount: 30000}사용자 123의 주문을 날짜 순서로 정렬 가능!
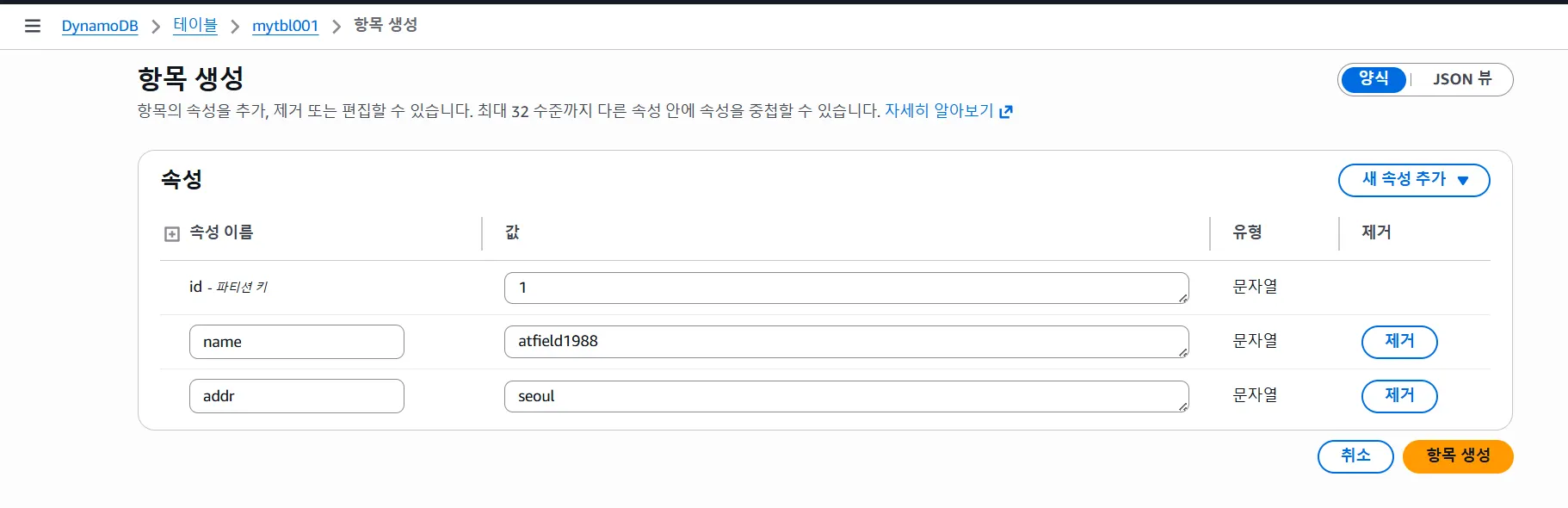
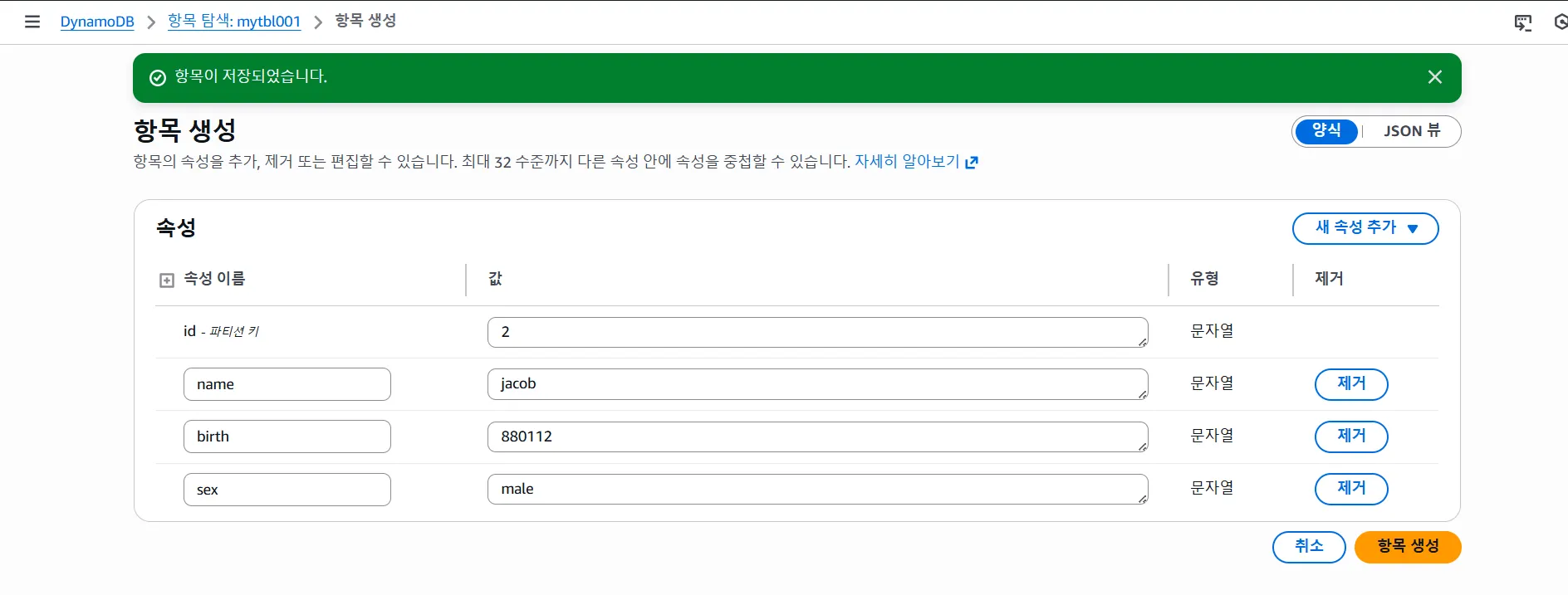
3. 속성 (Attribute)
각 항목(행)의 "데이터 필드"
예:
항목 1:
├─ UserID (파티션 키): 123
├─ OrderDate (정렬 키): 2025-01-15
├─ Amount (속성): 50000
├─ Status (속성): "completed"
├─ Items (속성): ["상품1", "상품2"] (리스트도 가능)
└─ Metadata (속성): {device: "mobile", ip: "192.168.1.1"} (객체도 가능)DynamoDB는 스키마 제약이 없어서 각 항목마다 다른 속성을 가질 수 있음
4. 용량 단위 (Capacity Units)
DynamoDB는 "읽기/쓰기 처리량"으로 과금
방식 1: 온디맨드 (On-Demand)
- 요청 수에 따라 자동 계산
- 트래픽 예측 어려울 때 좋음
- 약간 비쌈
방식 2: 프로비저닝된 용량 (Provisioned)
- 미리 읽기/쓰기 처리량 예약
- 트래픽 패턴을 알 때 좋음
- 더 저렴
- 초과하면 Throttle (거부) 발생
예:
온디맨드 vs 프로비저닝
├─ 작은 앱, 비정기적 트래픽 → 온디맨드 추천
└─ 대규모 앱, 예측 가능한 트래픽 → 프로비저닝 추천DynamoDB 사용 사례
Ⅰ) 세션 저장소
사용자_ID → {last_login, session_token, preferences}Ⅱ) 게임 순위표
GameID + PlayerRank → {PlayerName, Score, Timestamp}Ⅲ) 실시간 알림
UserID + NotificationID → {message, timestamp, read}Ⅳ) 제품 카탈로그 캐시
ProductID → {name, price, inventory, images}Ⅴ) 디바이스 상태 추적
DeviceID → {last_seen, status, metrics, location}Ⅵ) 쇼핑 카트
UserID → {items: [{product_id, quantity}], updated_at}특징:
- 매우 빠른 응답 시간 (밀리초)
- 자동 확장 (트래픽 증가시 자동 처리)
- 복잡한 SQL 조인 불필요
- 비용 효율적
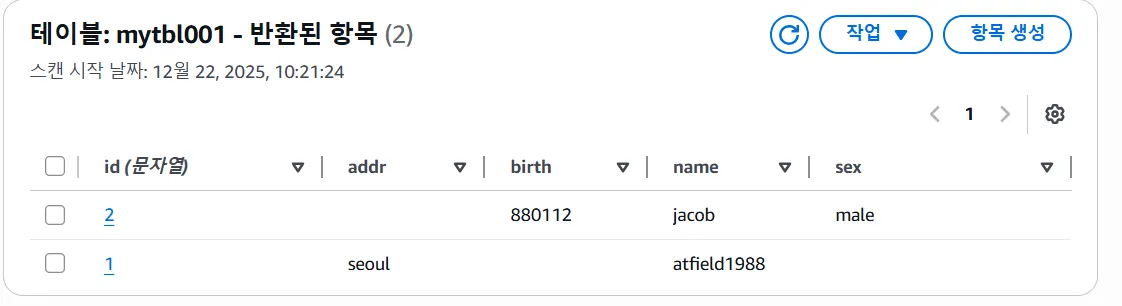
DynamoDB 만들어보기
 )
) )
) )
) )
)
7.5 기타 AWS 데이터베이스 서비스
1. Amazon DocumentDB (문서 DB)
MongoDB와 호환되는 문서 데이터베이스
특징:
- MongoDB 쿼리 언어 지원
- JSON 문서 형식
- 관계형 DB보다 유연
- DynamoDB보다 복잡한 쿼리 가능
MongoDB 자체를 사용하던 기존 앱을 AWS로 마이그레이션할 때 유용
2. Amazon Neptune (그래프 DB)
노드(Node)와 엣지(Edge)로 관계를 저장
데이터 구조:
- 노드: 사람, 제품, 장소 등
- 엣지: 사람-사람 관계 (친구, 팔로우), 사람-제품 관계 (구매, 선호)
- 엣지의 가중치: 얼마나 강한 관계인지
SQL로는 구현 어려운 복잡한 관계 쿼리가 매우 빠르고 효율적임
3. Amazon Timestream (시계열 DB)
시간이 지남에 따라 변하는 데이터를 저장
특징:
- 시간 + 값의 쌍
- 매우 높은 쓰기 처리량 (초당 수백만 건)
- 자동 데이터 집계
- 자동 만료 설정 (오래된 데이터 자동 삭제)
4. Amazon QLDB (원장 DB)
거래 기록을 변조할 수 없게 저장하는 데이터베이스
특징:
- 불변성: 한 번 기록된 데이터는 변경 불가
- 모든 거래 이력 추적 가능
- 암호학적으로 검증 가능
- 감사(Audit)에 최적
각 DB의 장단점
| DB | 장점 | 단점 | 비용 |
|---|---|---|---|
| RDS | 복잡한 쿼리, ACID | 성능 한계, 확장 어려움 | 고정 비용 |
| DynamoDB | 초고속, 자동 확장, 저비용 | 복잡한 쿼리 불가, 스키마 관리 필요 | 사용량 기반 |
| DocumentDB | 유연한 스키마, 문서형 | 중간 성능 | 고정 비용 |
| Neptune | 그래프 쿼리 최적 | 학습곡선, 비용 | 고정 비용 |
| Timestream | 시계열 최적화, 대용량 | 시계열만 | 사용량 기반 |
| QLDB | 불변성, 감사 완벽 | 트랜잭션 제한 | 사용량 기반 |
8. 알아 두면 좋은 AWS 서비스 (Route 53, Lambda, ECS)
8.1 Amazon Route 53
Route 53란?
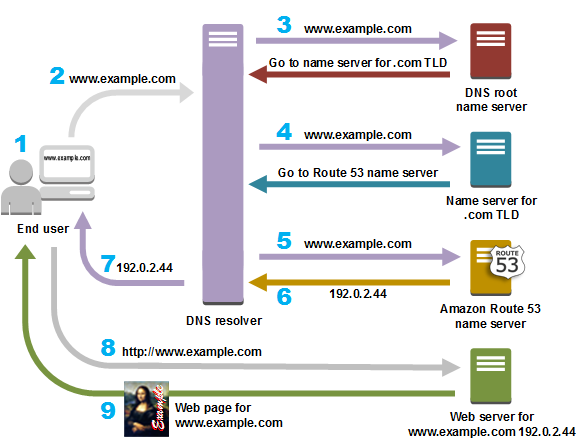
Route 53 = AWS의 DNS(Domain Name Service) 서비스
사용자의 요청 흐름:
1. www.example.com에 접속하고 싶다
↓
2. Route 53에 DNS 쿼리 (도메인명 → IP 주소)
↓
3. Route 53이 IP 주소 응답
↓
4. 사용자가 해당 IP로 접속
↓
5. 웹 사이트 표시Route 53의 기능
| 기능 | 설명 |
|---|---|
| DNS 해석 | 도메인명을 IP 주소로 변환 |
| 헬스 체크 | 리소스 상태 모니터링 |
| 라우팅 정책 | 요청을 여러 엔드포인트로 분산 |
| 도메인 등록 | 도메인명 직접 구매 가능 |
| ALIAS 레코드 | AWS 리소스와 연결 |
Route 53의 라우팅 정책
1. 단순 라우팅 (Simple Routing)
특징:
- 가장 기본적인 방식
- 도메인 → 단일 IP 주소 매핑
- 헬스 체크 없음
사용 사례:
- 단일 서버/인스턴스가 있을 때
- 웹 사이트, 블로그
2. 가중치 기반 라우팅 (Weighted Routing)
특징:
- 비율에 따라 트래픽 분산
- 70% → 서버 A, 30% → 서버 B
사용 사례:
- A/B 테스팅
- 카나리 배포 (단계적,점진적 배포)
- 트래픽 점진적 마이그레이션
예시:
새로운 서버: 10% 트래픽
기존 서버: 90% 트래픽
→ 점진적으로 증가
3. 지연시간 기반 라우팅 (Latency Routing)
특징:
- 사용자 위치와 가장 가까운 서버로 라우팅
- 응답 속도 최소화
사용 사례:
- 글로벌 서비스
- 다중 리전 배포
예시:
서울 사용자 → 서울 리전 서버
도쿄 사용자 → 도쿄 리전 서버
4. 지리 위치 기반 라우팅 (Geolocation Routing)
특징:
- 사용자의 지리적 위치에 따라 라우팅
- 지역별 콘텐츠 분배
사용 사례:
- 지역별 언어 서비스
- 지역 규제 준수 (GDPR 등)
- 지역별 CDN 분산
예시:
한국 → 한국 버전 제공
일본 → 일본 버전 제공
5. 다중 응답 라우팅 (Multivalue Routing)
특징:
- 여러 IP 주소 응답 (최대 8개)
- 클라이언트가 선택
사용 사례:
- 로드 밸런싱
- 간단한 가용성 보장
차이점: ELB처럼 균등 분산, 헬스 체크 지원
6. 장애 조치 라우팅 (Failover Routing)
특징:
- Active-Standby 구성
- Primary 서버 장애 시 자동 Standby로 전환
사용 사례:
- 고가용성 구성
- 재해 복구 (DR)
동작:
Primary 정상 → Primary 사용
Primary 장애 → Secondary로 자동 전환
Route 53 동작 예시
8.2 AWS Lambda
Lambda란?
"서버리스 컴퓨팅 서비스"
- 서버 관리 불필요
- 함수만 작성하고 실행
- 사용한 시간만큼만 요금 지불
Lambda vs EC2 비교
| 항목 | Lambda | EC2 |
|---|---|---|
| 서버 관리 | 불필요 (AWS 관리) | 필요 |
| 스케일링 | 자동 | 수동 또는 ASG |
| 비용 모델 | 실행 시간 (ms) 기반 | 시간 기반 |
| 시작 시간 | 수초 | 수분 |
| 최대 실행 시간 | 15분 | 무제한 |
| 메모리 | 128MB ~ 10,240MB | 자유 |
| 사용 사례 | 이벤트 기반 | 장시간 실행 |
Lambda 지원 언어
Python (가장 인기)
Node.js (JavaScript)
Java
C# (.NET)
Go
Ruby
커스텀 런타임Lambda 함수의 구조
import boto3
import json
# AWS 서비스 클라이언트 초기화
s3_client = boto3.client('s3')
dynamodb = boto3.resource('dynamodb')
# Lambda 핸들러 함수
def lambda_handler(event, context):
// event: 트리거로부터의 입력 데이터
// context: 런타임 정보 (메모리, 함수명, 요청ID 등)
print(f"Event: {json.dumps(event)}")
# 트리거
bucket_name = event['Records'][0]['s3']['bucket']['name']
//event에서 S3 트리거 정보를 읽어옴
key = event['Records'][0]['s3']['object']['key']
//key: 업로드된 파일의 경로
# S3에서 파일 다운로드
s3_client.download_file(bucket_name, key, '/tmp/file.txt')
# 데이터 처리
result = process_file('/tmp/file.txt')
# 응답 반환
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Success',
'result': result
})
}
def process_file(file_path):
with open(file_path, 'r') as f:
content = f.read()
return content.upper() Lambda의 이벤트 소스 (트리거)
Synchronous (동기) 호출
클라이언트의 응답을 기다림
이벤트 소스:
- API Gateway ▶ Lambda ▶ 응답 (REST API)
- ALB/ELB ▶ Lambda ▶ 응답 (로드 밸런서)
- CloudFront ▶ Lambda ▶ 응답 (엣지 함수)
- 콘솔 또는 CLI 직접 호출
Asynchronous (비동기) 호출
즉시 202 응답 (처리는 나중에)
이벤트 소스:
- S3 (파일 업로드 시)
- SNS (메시지 발행 시)
- SES (이메일 수신 시)
- CloudFormation (스택 생성 시)
- EventBridge (예약된 이벤트)
Poll 기반 (스트림 처리)
Lambda가 이벤트 소스를 계속 확인
이벤트 소스:
- Kinesis Streams
- DynamoDB Streams
- SQS
Lambda 이벤트 기반 실행 예시
예시 1: S3 파일 업로드 시 썸네일 생성
import boto3
from PIL import Image
import io
s3_client = boto3.client('s3')
def lambda_handler(event, context):
"""S3에 이미지 업로드되면 자동으로 썸네일 생성"""
# 이벤트에서 버킷 및 키 추출
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# S3에서 이미지 다운로드
response = s3_client.get_object(Bucket=bucket, Key=key)
image_data = response['Body'].read()
# PIL로 이미지 크기 조정
image = Image.open(io.BytesIO(image_data))
image.thumbnail((100, 100)) # 100x100 썸네일
# 처리된 이미지를 바이트로 변환
thumb_buffer = io.BytesIO()
image.save(thumb_buffer, format='JPEG')
thumb_data = thumb_buffer.getvalue()
# 썸네일을 다른 S3 버킷에 업로드
s3_client.put_object(
Bucket=f'{bucket}-resized',
Key=f'thumb-{key}',
Body=thumb_data,
ContentType='image/jpeg'
)
return {
'statusCode': 200,
'body': f'Thumbnail created for {key}'
}트리거 설정:
S3 버킷 → 이벤트 알림 → Lambda 함수
"s3:ObjectCreated:*"Lambda 설정 항목
| 항목 | 설명 | 범위 |
|---|---|---|
| 메모리 | 할당 메모리 | 128MB ~ 10,240MB |
| 실행 시간 | 최대 실행 시간 | 1초 ~ 15분 |
| 임시 스토리지 | /tmp 용량 | 512MB ~ 10,240MB |
| 환경 변수 | 설정값 저장 | 자유 |
| VPC | VPC 연결 | Optional |
| 실행 역할 | IAM 역할 | 필수 |
| 레이어 | 라이브러리/코드 공유 | 최대 5개 |
Lambda의 제한사항
제약 사항:
- 최대 실행 시간: 15분
- 최대 메모리: 10GB
- 최대 /tmp 스토리지: 10GB
- 최대 코드 크기: 50MB (압축)
- 최대 레이어 크기: 250MB (압축)
- 동시 실행: 1000 (기본값, 증설 가능)
- 환경 변수: 최대 4KB
해결 방안:
- 장시간 작업 → EC2 또는 ECS 사용
- 대용량 코드 → Container Image 사용 (25GB까지)
- 높은 동시성 → 미리 동시성 예약
Lambda 실습 예시
실습 1: S3 트리거로 이미지 리사이징
목표: S3에 이미지 업로드 → 자동으로 썸네일 생성
S3 버킷 생성 이미지 업로드
이미지 업로드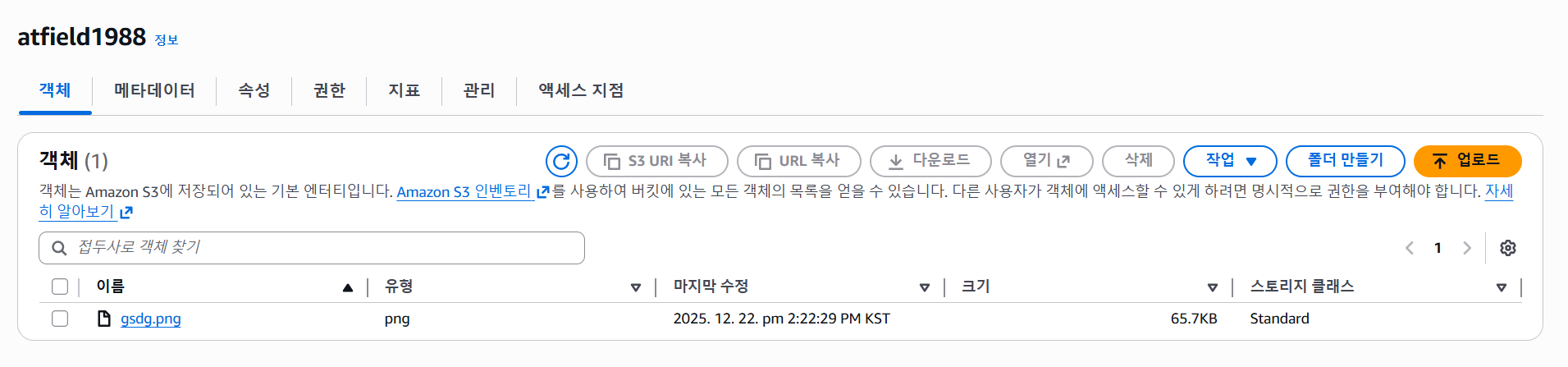
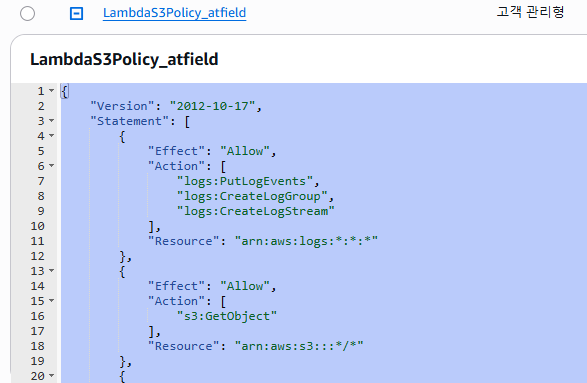
정책 생성 (IAM Policy):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:PutLogEvents",
"logs:CreateLogGroup",
"logs:CreateLogStream"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": "arn:aws:s3:::*/*"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": "arn:aws:s3:::*/*"
}
]
}
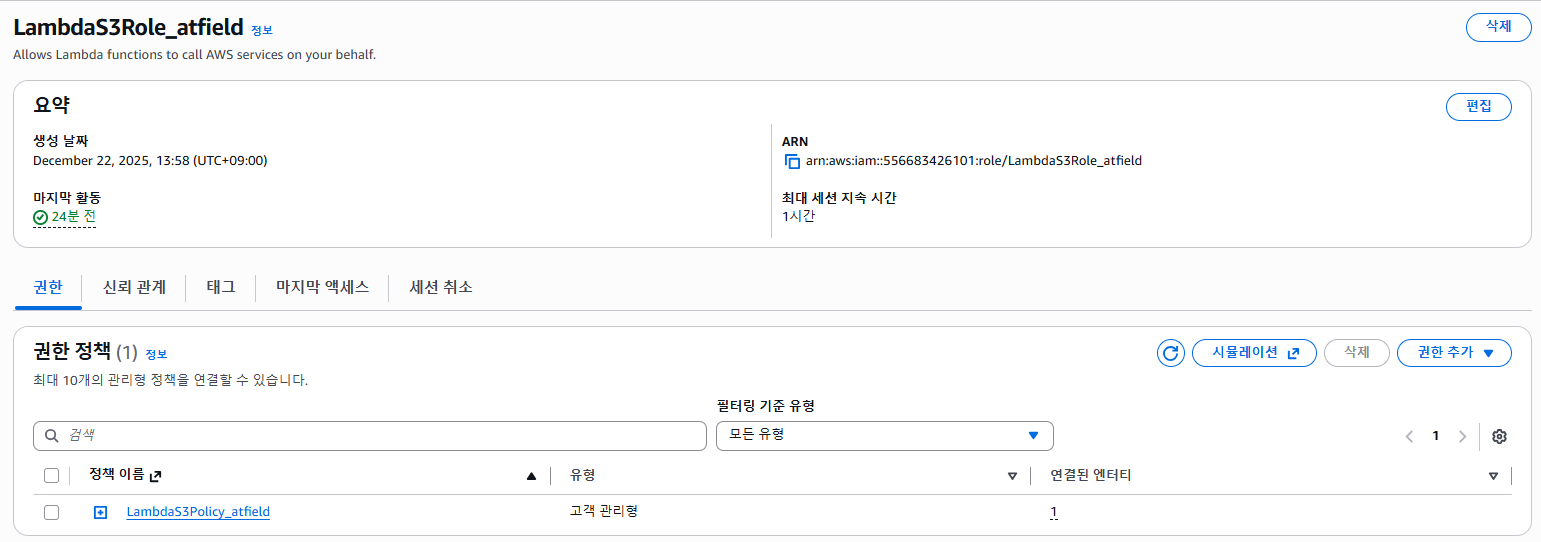
실행 역할 (IAM Role):
배포 패키지 작성(예제코드)
import boto3
import os
import sys
import uuid
from urllib.parse import unquote_plus
from PIL import Image
import PIL.Image
s3_client = boto3.client('s3')
def resize_image(image_path, resized_path):
with Image.open(image_path) as image:
image.thumbnail(tuple(x / 2 for x in image.size))
image.save(resized_path)
def lambda_handler(event, context):
for record in event['Records']:
bucket = record['s3']['bucket']['name']
key = unquote_plus(record['s3']['object']['key'])
tmpkey = key.replace('/', '')
download_path = '/tmp/{}{}'.format(uuid.uuid4(), tmpkey)
upload_path = '/tmp/resized-{}'.format(tmpkey)
s3_client.download_file(bucket, key, download_path)
resize_image(download_path, upload_path)
s3_client.upload_file(upload_path, '{}-resized'.format(bucket), 'resized-{}'.format(key))mkdir package
pip install \
--platform manylinux2014_x86_64 \
--target=package \
--implementation cp \
--python-version 3.12 \
--only-binary=:all: --upgrade \
pillow boto3cd package
zip -r ../lambda_function.zip .
cd ..
zip lambda_function.zip lambda_function.pyLambda 함수 생성
.zip파일 업로드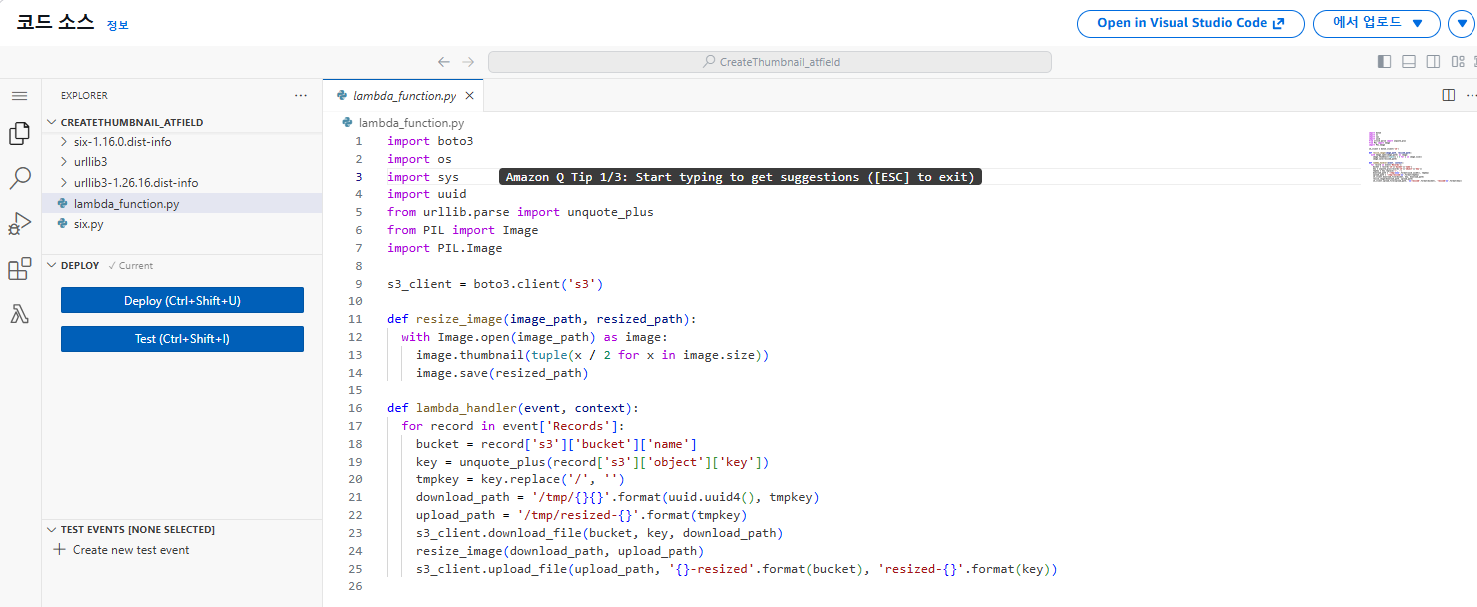
Amazon S3 트리거를 구성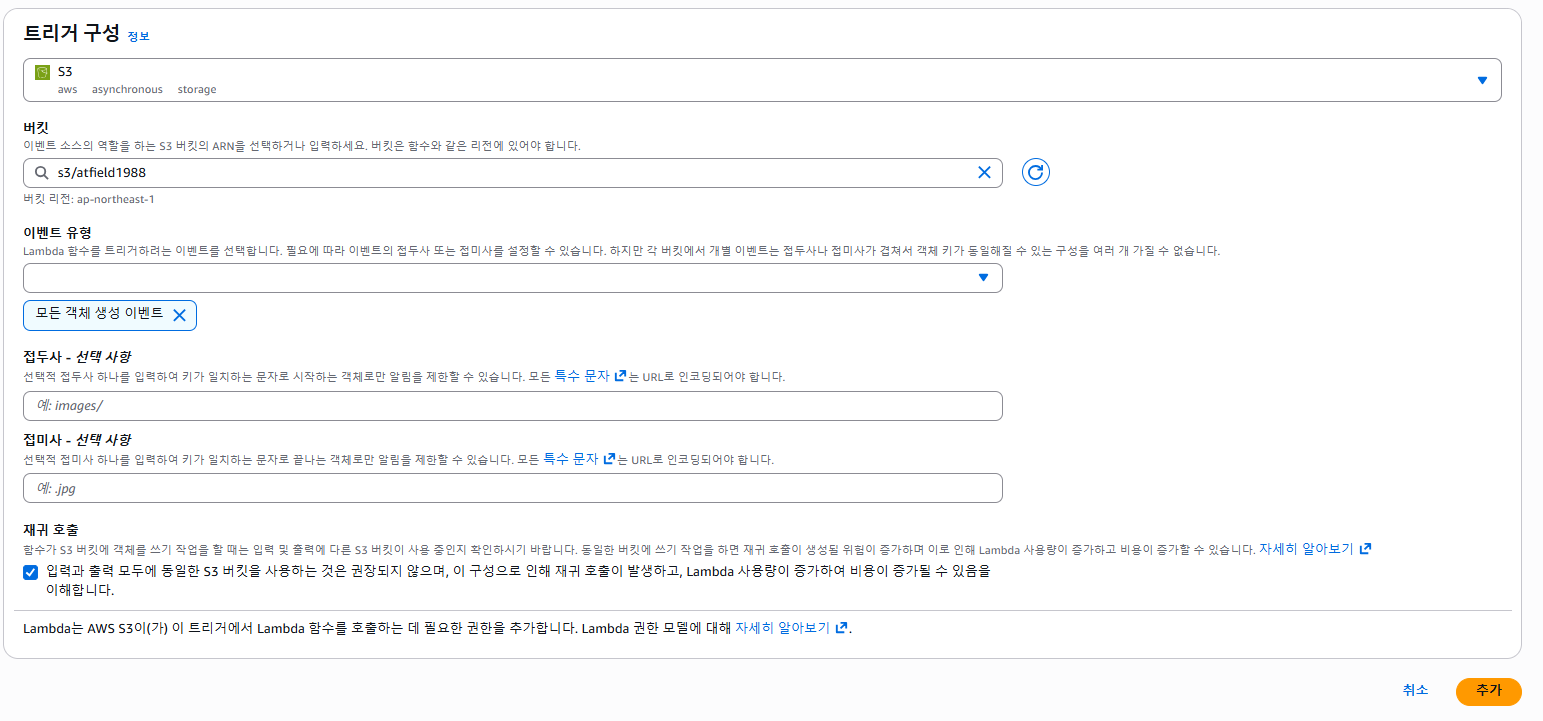
두 번째 버킷 확인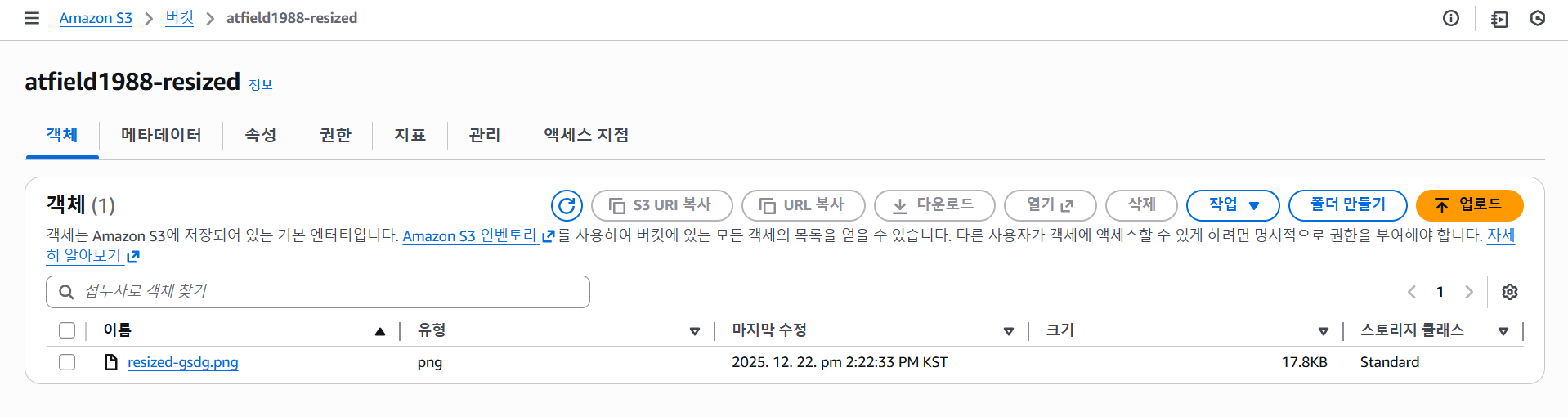
8.3 AWS 컨테이너 서비스
컨테이너란?
컨테이너 = 가벼운 가상 머신
특징:
- 가볍다 (가상머신은 GB, 컨테이너는 MB)
- 빠르다 (초단위 시작)
- 이식 가능 (어디서나 동일하게 실행)
- 격리된 환경 (프로세스 격리)
AWS 컨테이너 서비스 체계
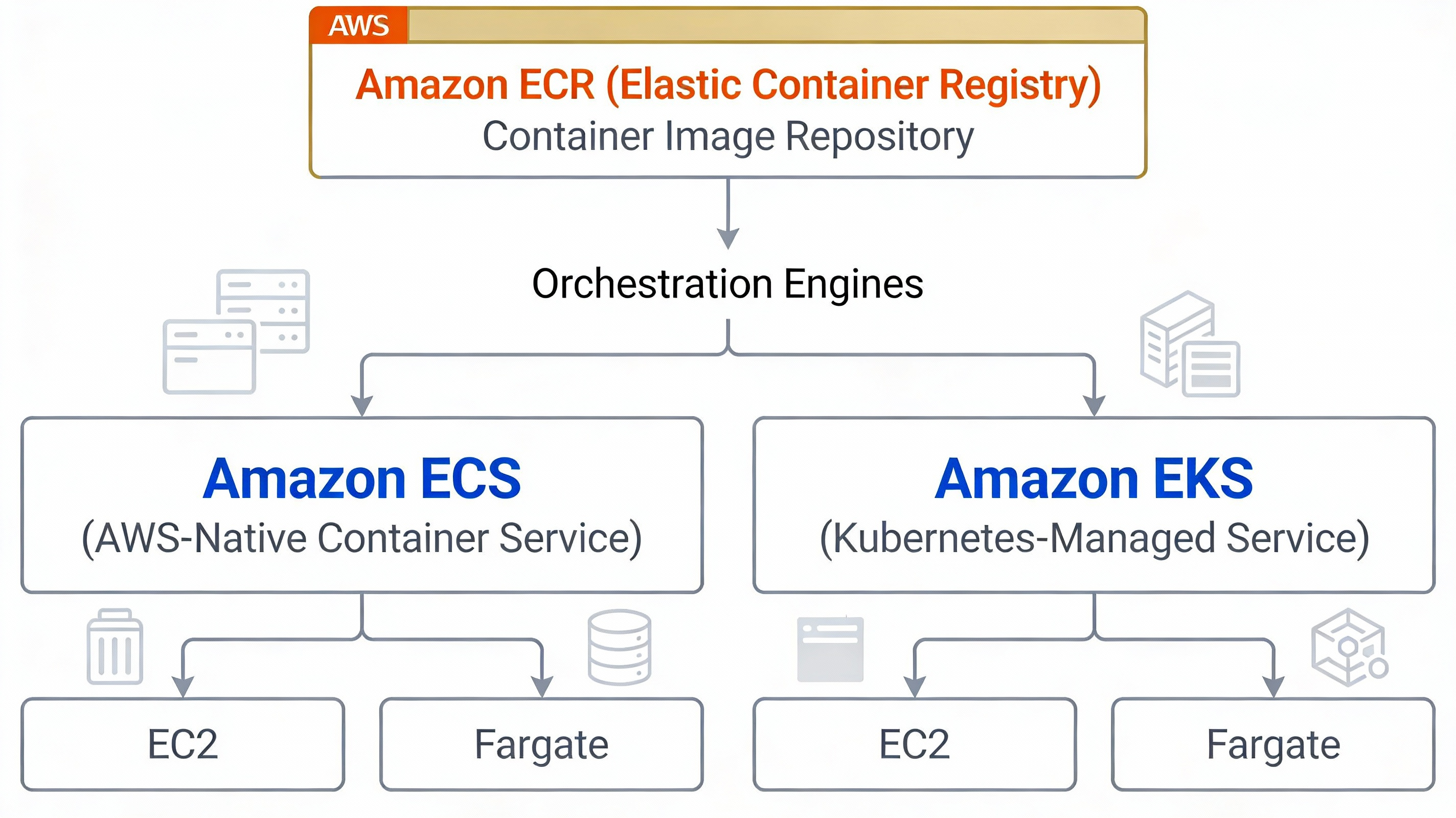
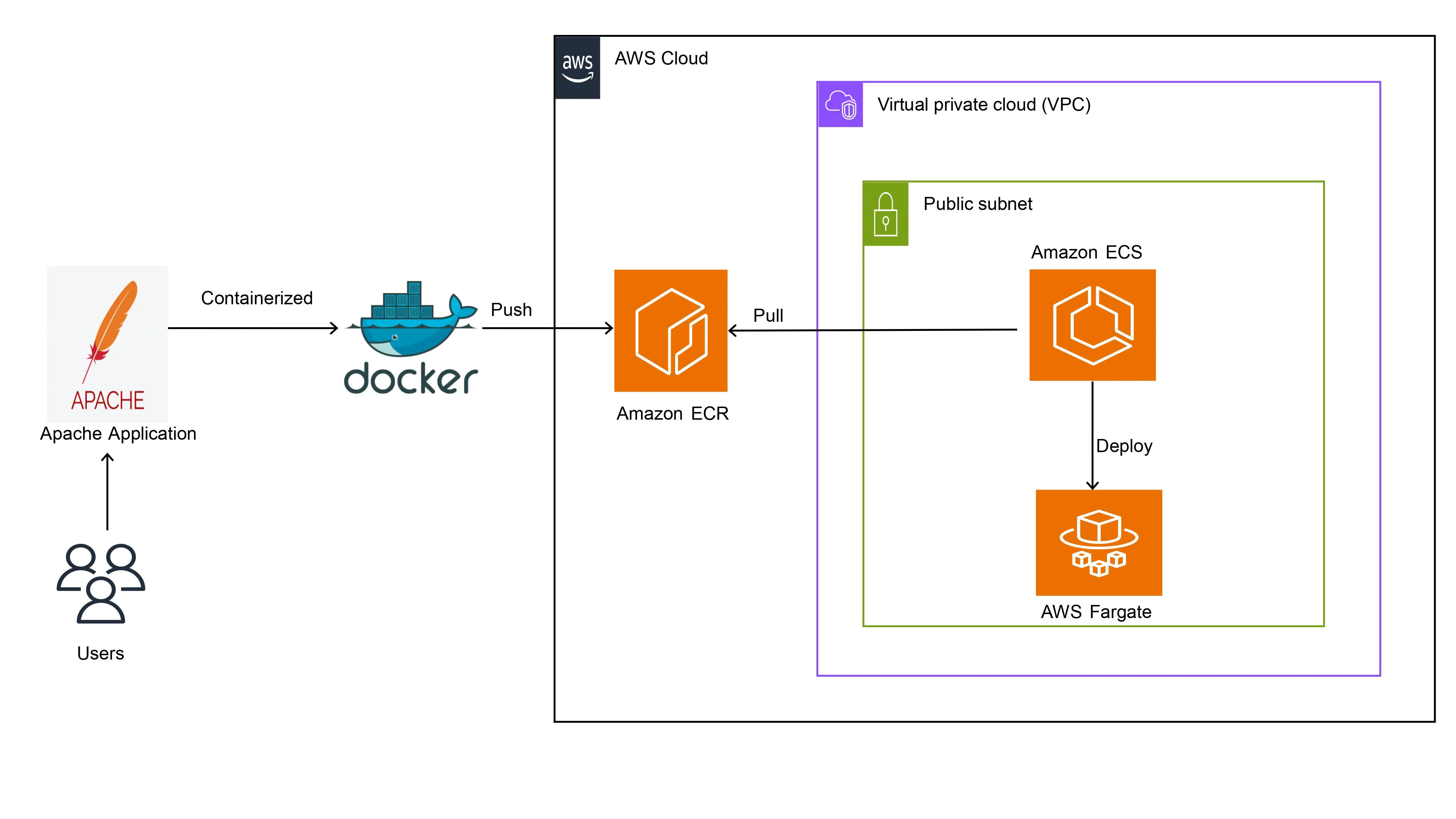
Amazon ECR (Elastic Container Registry)
용도: 컨테이너 이미지 저장소
특징:
- Docker Hub처럼 이미지 저장
- Private 레지스트리
- IAM 권한 제어 가능
- 이미지 스캔 (취약점 검사)
- 수명 주기 정책 (자동 삭제)
- CloudWatch 로깅 가능
가격: 저장된 이미지 용량에 따라 청구
사용 흐름:
- Dockerfile 작성
- 이미지 빌드
- ECR에 푸시 (docker push)
- ECS/EKS에서 풀 (docker pull)
Amazon ECS (Elastic Container Service)
ECS의 개념
용도: AWS 네이티브 컨테이너 오케스트레이션
ECS = EC2 인스턴스에서 Docker 컨테이너 실행 관리
구성 요소:
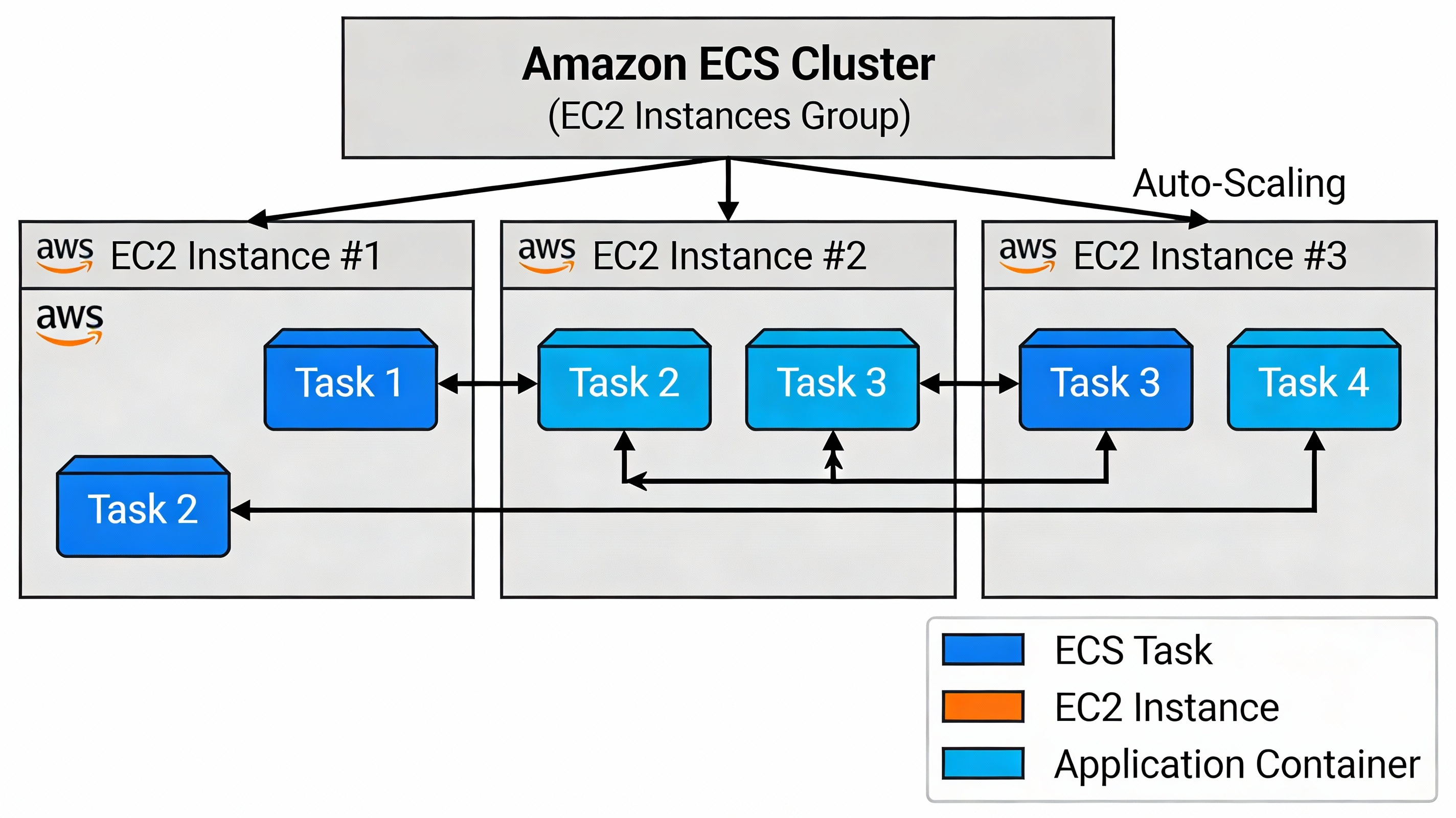
Task (작업):
- 1개 이상의 컨테이너 실행 단위
- EC2 인스턴스 위에서 실행
- 자동 스케일링, 헬스 체크 가능
ECS 구성 요소 상세
ECS Cluster (클러스터)
- EC2 인스턴스 그룹
- 같은 보안 그룹, VPC 내 인스턴스들
Task Definition (작업 정의)
- Docker 이미지 및 실행 설정
- CPU/메모리 할당
- 환경 변수, 마운트 포인트 등
Task (작업)
- Task Definition을 바탕으로 실행되는 인스턴스
- 컨테이너 1개 이상 포함
Service (서비스)
- Task의 집합 관리
- 원하는 Task 개수 유지
- 로드 밸런싱, 자동 재시작
ECS Task 정의 예시 (JSON)
{
"family": "web-app",
"networkMode": "bridge",
"containerDefinitions": [
{
"name": "web-container",
"image": "123456789012.dkr.ecr.us-east-1.amazonaws.com/my-app:latest",
"memory": 512,
"cpu": 256,
"essential": true,
"portMappings": [
{
"containerPort": 80,
"hostPort": 80,
"protocol": "tcp"
}
],
"environment": [
{
"name": "APP_ENV",
"value": "production"
}
],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/web-app",
"awslogs-region": "us-east-1",
"awslogs-stream-prefix": "ecs"
}
}
}
]
}AWS Fargate
Fargate란?
"서버리스 컨테이너 실행"
기존 ECS (EC2 기반): EC2 구매 → EC2 관리 → Docker 실행
Fargate (서버리스): Docker 이미지만 제공 → AWS가 모든 것 관리
EC2 vs Fargate 비교
| 항목 | ECS on EC2 | Fargate |
|---|---|---|
| 서버 관리 | 필요 | 불필요 |
| 비용 | 저렴 (EC2 구매) | 높음 (편의료) |
| 스케일링 | 수동 또는 자동 | 자동 |
| 시작 시간 | 느림 | 빠름 |
| 메모리 | 자유 | 정해진 조합 |
| 적합한 상황 | 높은 트래픽 | 일시적, 개발 |
Amazon EKS (Elastic Kubernetes Service)
EKS란?
Kubernetes = 대규모 컨테이너 오케스트레이션
EKS = AWS에서 관리하는 Kubernetes
특징:
- Kubernetes 표준 API 사용 가능
- AWS 서비스와 통합 (IAM, ALB 등)
- 자동 스케일링, 로드 밸런싱
- 다중 가용 영역 지원
- 오픈소스 커뮤니티 활용 가능
사용 계층: ┌─────────────────────────────┐ │ 사용자 (애플리케이션) │ ├─────────────────────────────┤ │ Kubernetes (쿠버네티스 관리)│ ├─────────────────────────────┤ │ EKS (AWS 관리형) │ └─────────────────────────────┘
EKS vs ECS 비교
| 항목 | ECS | EKS |
|---|---|---|
| 학습곡선 | 낮음 (AWS 특화) | 높음 (Kubernetes) |
| 이식성 | AWS 종속 | 표준 Kubernetes |
| 조직 규모 | 중소 팀 | 대규모 팀 |
| 멀티 클라우드 | 불가능 | 가능 |
| 비용 | 저렴 | 비쌈 (Control Plane) |
AWS 컨테이너 서비스 아키텍처 예시
시나리오: MSA 배포
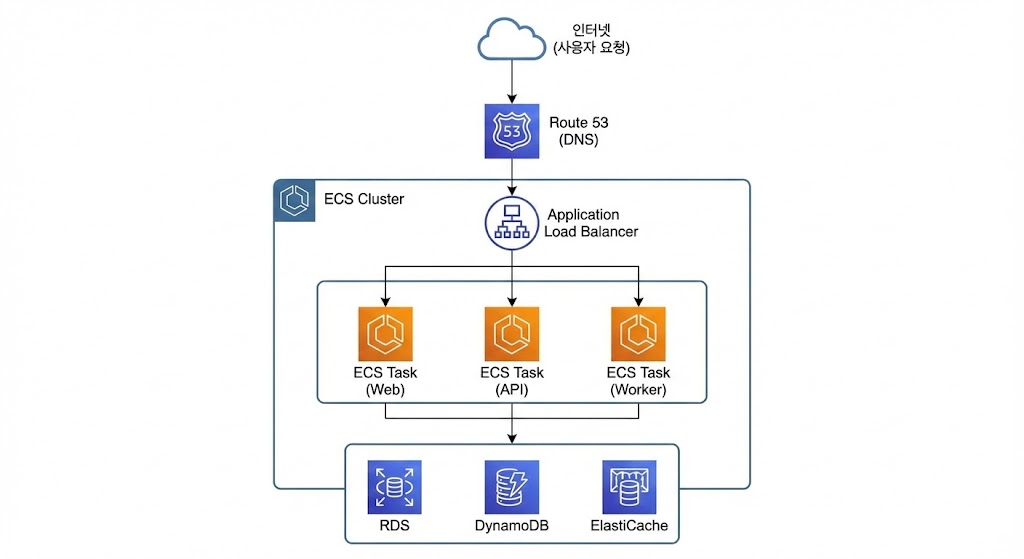
관련 AWS 서비스
상위 계층 (API/라우팅):
- Route 53 (DNS)
- API Gateway
- Load Balancer (ALB, NLB)
컨테이너 계층:
- ECR (이미지 저장)
- ECS (오케스트레이션)
- EKS (Kubernetes)
- Fargate (서버리스 실행)
하위 계층 (데이터/저장):
- RDS (관계형 DB)
- DynamoDB (NoSQL)
- S3 (객체 저장소)
- ElastiCache (캐시)
모니터링/로깅:
- CloudWatch (메트릭, 로그)
- X-Ray (분산 추적)
- CloudTrail (감사 로그)
Route 53 라우팅 정책 선택 기준
| 정책 | 언제 사용? | 장점 | 단점 |
|---|---|---|---|
| Simple | 단일 엔드포인트 | 간단함 | 장애 대응 불가 |
| Weighted | A/B 테스트 | 카나리 배포 | 수동 조정 |
| Latency | 글로벌 앱 | 응답 속도 | 설정 복잡 |
| Geolocation | 지역별 서비스 | GDPR 준수 | 지연 시간 증가 |
| Failover | DR 구성 | 고가용성 | 복잡한 설정 |
컴퓨팅 서비스 비교
| 서비스 | EC2 | Lambda | ECS | EKS |
|---|---|---|---|---|
| 관리 | 수동 | 완전 자동 | 반자동 | 반자동 |
| 비용 | 낮음 | 아주 낮음 (사용 기반) | 낮음-중간 | 높음 |
| 학습곡선 | 낮음 | 낮음 | 낮음 | 높음 |
| 실행 시간 | 무제한 | 15분 | 무제한 | 무제한 |
| 이식성 | AWS 종속 | AWS 종속 | 높음 | 매우 높음 |
| 최적 사용 | 장시간 실행 | 이벤트 기반 | 컨테이너 | 멀티 클라우드 |
'SK Shieldus Rookies 29' 카테고리의 다른 글
| [SK shieldus Rookies 29기] 34일차 (0) | 2026.01.14 |
|---|---|
| [SK shieldus Rookies 29기] 33일차 (0) | 2026.01.14 |
| [SK shieldus Rookies 29기] 31일차 (0) | 2026.01.14 |
| [SK shieldus Rookies 29기] 30일차 (1) | 2026.01.14 |
| [SK shieldus Rookies 29기] 29일차 (1) | 2026.01.14 |



