
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- sk 쉴더스 루키즈
- 모의침투
- 개인정보보호
- AI #취업
- rocky linux#siem#project#threat detection#soc#onpremise#ids#python#csv#pipeline#kali linux#DVWA#security monitoring
- kisa #보안관제
- 시스템-네트워크 보안 기술
- CERT
- #루키즈
- 모듈 프로젝트
- 보고서
- 기술 특강 및 OT
- 클라우드기반 보안 시스템 구축/운영 실무
- 클라우드 기반
- Foxyproxy#install#setting#firefox
- Kali#Linux#KALI#LINUX#INSTALL#github#설치
- 클라우드 보안 기반
- 인프라 활용을 위한 파이썬
- Kali#Linux#Brute#Force#Attack#Test#DVWA#Hacking#Low#무차별#대입#공격#해킹
- sk shieldus
- 29기
- VMWARE#INSTALL#설치
- DVWA#INSTALL#github#security#kali#linux
- 루키즈
- 모듈프로젝트
- DVWA#Brute#Force#Attack#Test#Kali#Linux#Medium#Level#sleep
- 쉴더스
- 클라우드 보안 기술
- 애플리케이션 보안 기술
- Case Study
- Today
- Total
이것저것
[SK shieldus Rookies 29기] 29일차 본문
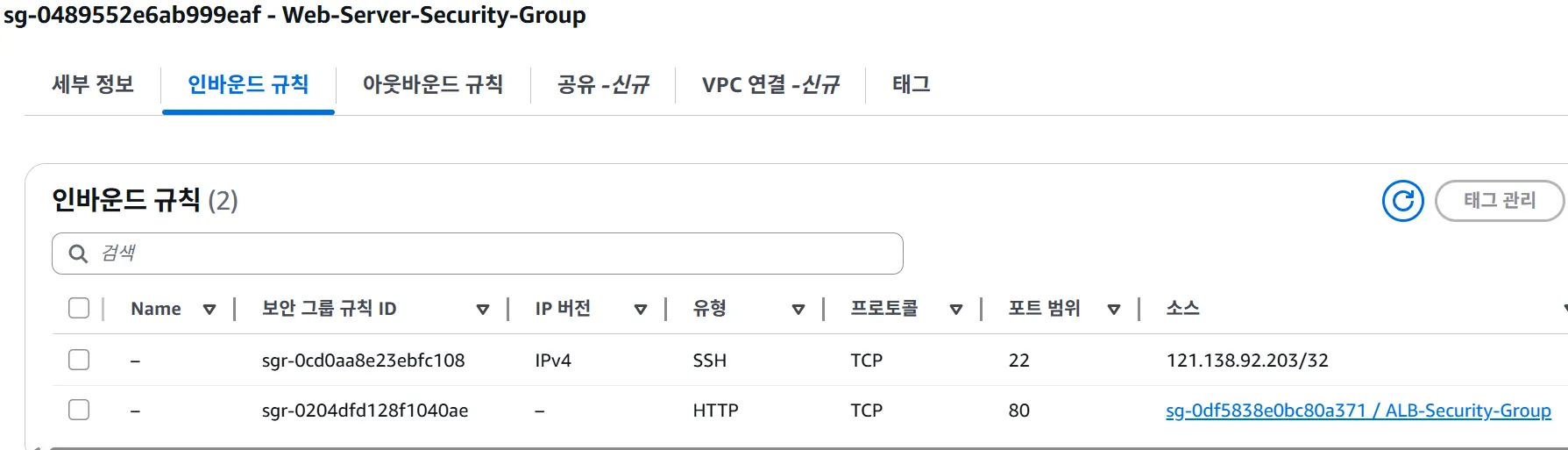
6.8 보안 그룹 (Security Group)
보안 그룹이란?
인스턴스 레벨의 가상 방화벽
방화벽 기능:
- 어떤 포트에서 데이터를 받을지 결정 (Inbound)
- 어떤 포트로 데이터를 보낼지 결정 (Outbound)
- 어느 IP/보안 그룹에서 오는 트래픽을 허용할지 결정
 )
)
기본값
| 트래픽 방향 | 기본 정책 | 설명 |
|---|---|---|
| Inbound (들어오는 트래픽) | 모두 차단 ❌ | 명시적으로 허용한 규칙만 접근 가능 |
| Outbound (나가는 트래픽) | 모두 허용 ✅ | 모든 외부로의 통신 허용 |
보안 그룹 규칙 예시
웹 서버 보안 그룹 – Inbound Rules
| Type | Protocol | Port | Source | 설명 |
|---|---|---|---|---|
| SSH | TCP | 22 | 0.0.0.0/0 | 원격 접속 |
| HTTP | TCP | 80 | 0.0.0.0/0 | 웹 브라우저 |
| HTTPS | TCP | 443 | 0.0.0.0/0 | 보안 웹 |
| Custom | TCP | 3000 | 10.0.0.0/16 | VPC 내부 |
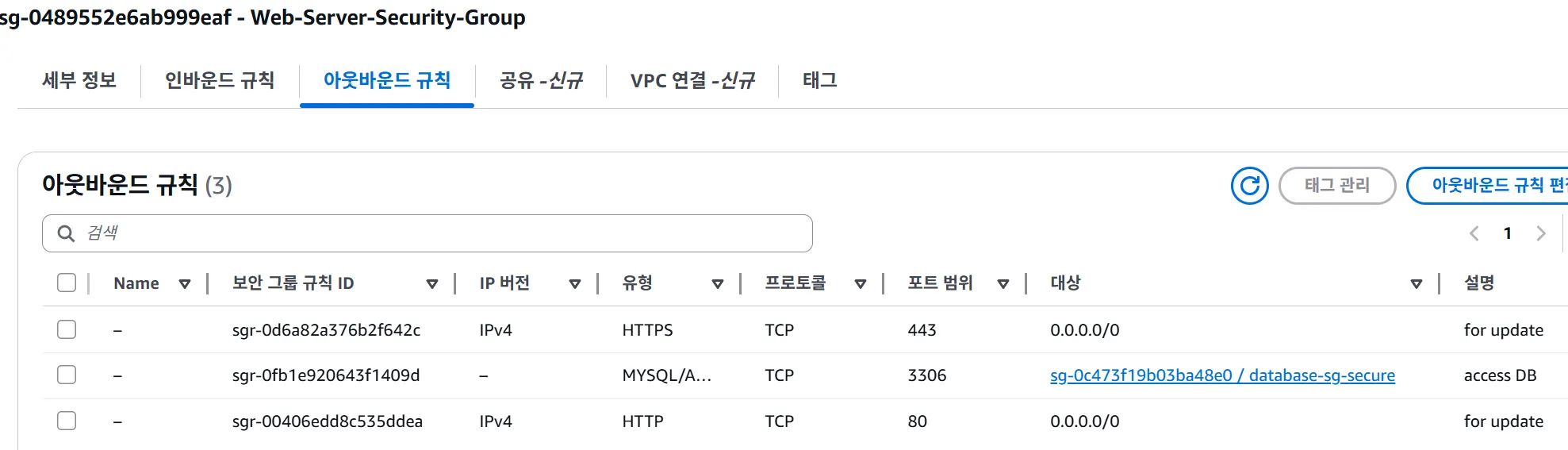
웹 서버 보안 그룹 – Outbound Rules
| Type | Protocol | Port | Destination | 설명 |
|---|---|---|---|---|
| All | All | All | 0.0.0.0/0 | 모두 허용 |
중요 특징
Whitelist 방식 (명시된 것만 허용)
- 허용 규칙에 명시된 것만 들어옴
상태 추적
- Outbound 허용 → 자동으로 Inbound 응답 허용
- HTTP 요청 → 응답이 자동으로 들어옴
참조 가능
- 다른 보안 그룹을 Source로 지정 가능
- "ELB 보안 그룹에서 오는 트래픽만 허용"
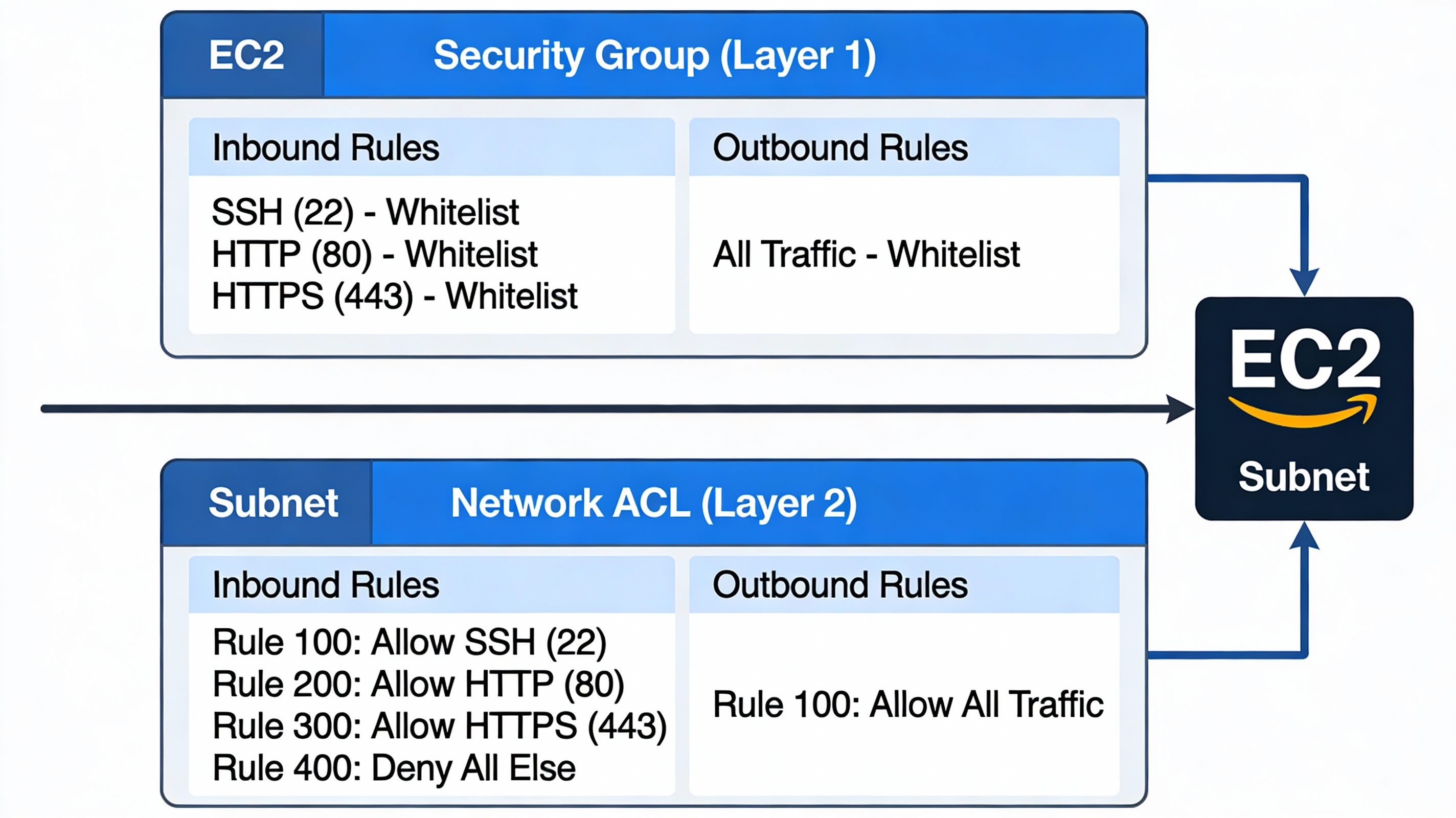
6.9 네트워크 ACL (Access Control List)
네트워크 ACL이란?
Subnet 레벨의 네트워크 방화벽
| 방화벽 계층 | 적용 범위 |
|---|---|
| 보안 그룹 | 인스턴스 레벨 |
| 네트워크 ACL | Subnet 레벨 |
기본값
Inbound & Outbound: 기본값-> 모두 허용 (✅)
보안 그룹 vs 네트워크 ACL
| 항목 | 보안 그룹 | 네트워크 ACL |
|---|---|---|
| 계층 | 인스턴스 | Subnet |
| 기본 Inbound | 차단 (❌) | 허용 (✅) |
| 기본 Outbound | 허용 (✅) | 허용 (✅) |
| Whitelist | ✅ 명시적 허용 | ✅ 순서대로 검사 |
| 상태 추적 | ✅ 있음 | ❌ 없음 |
| 규칙 번호 | 없음 | 있음 (순서 중요) |
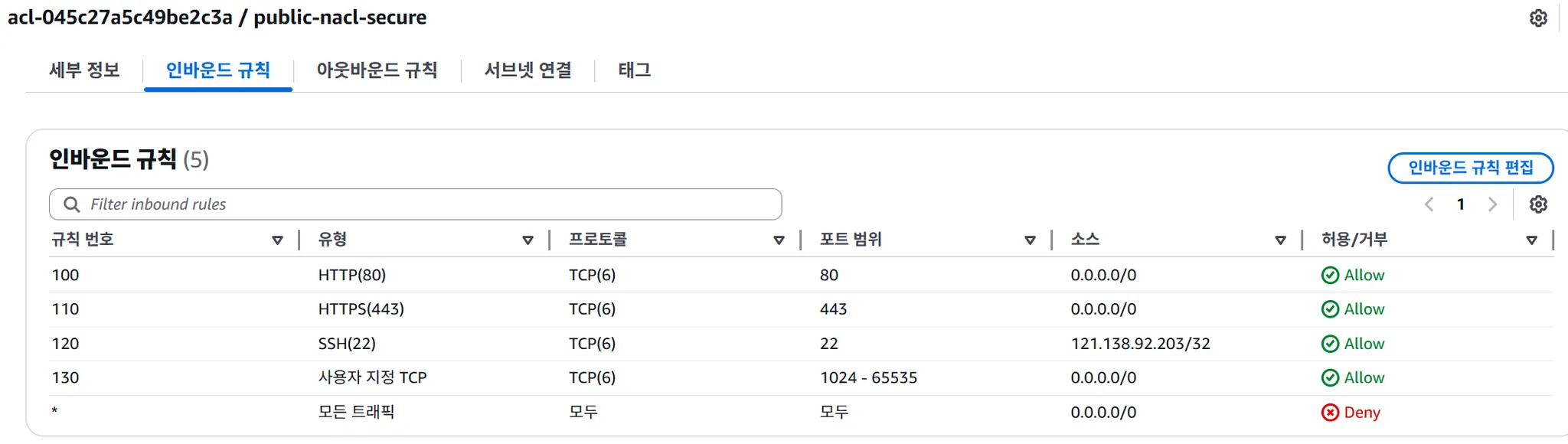
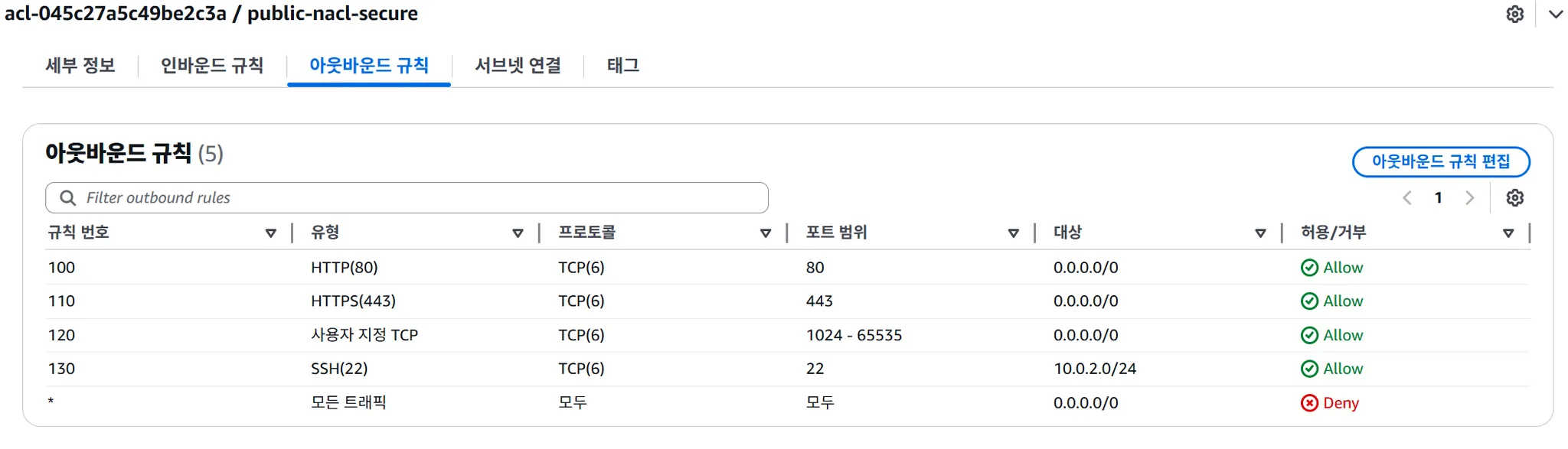
NACL 규칙 번호의 중요성
규칙 번호가 작을수록 우선순위가 높음:
| 규칙 번호 | Type | Port | Action | 비고 |
|---|---|---|---|---|
| 100 | HTTP | 80 | Allow | ← 우선 실행 |
| 110 | HTTPS | 443 | Allow | |
| 120 | All | All | Deny | ← 나중에 실행 |
결과: 80, 443 포트는 허용, 나머지는 차단
 )
)
6.10 VPC 연결
1. VPC Peering (VPC 피어링)
여러 VPC를 직접 연결
VPC-A (10.0.0.0/16)
↕ VPC Peering
VPC-B (10.1.0.0/16)특징
직접 연결 (피어투피어)
라우팅 테이블 설정 필요
간단하고 저비용
한 떄 이슈가 되었던 스트리밍 회사들의 그리드 전송 방식과 한 번 연관지어서 생각을 해보면 좋을 듯!
2. Transit Gateway (전송 게이트웨이)
여러 VPC와 온프레미스를 중앙에서 관리
Transit Gateway (허브)
↕
┌─────────────┼─────────────┐
↓ ↓ ↓
VPC-A VPC-B 온프레미스
(10.0/16) (10.1/16)
특징:
- 중앙 집중식 (Hub & Spoke)
- 여러 VPC/온프레미스 한번에 관리
- 복잡한 네트워크에 적합
- 보안 및 감사가 용이
3. VPN (Virtual Private Network)
보안 터널을 통해 온프레미스와 VPC 연결
온프레미스
↕ VPN Tunnel (암호화)
VPC (AWS 클라우드)특징:
- 암호화된 터널
- 인터넷 경유 (느림)
- 보안이 강함
VPN을 사용하지 않는 경우
VPN을 사용하지 않고 웹사이트에 연결하면 인터넷 서비스 제공 업체, 즉 ISP(SK Broadband, KT, U+ 등)를 통해 사이트로 연결됩니다. ISP는 웹사이트가 고객님을 식별하는 데 사용할 수 있는 고유한 IP 주소를 할당합니다. ISP는 고객님의 트래픽을 처리하기 때문에, 고객님이 어떤 웹사이트를 방문하는지도 확인할 수 있습니다. 그리고 고유 IP 주소를 통해 고객님과 고객님의 활동을 연결지을 수 있습니다.
VPN을 사용하는 경우
VPN을 사용해 인터넷에 연결하면 기기의 VPN 앱(VPN 클라이언트)이 VPN 서버와의 보안 연결을 구축합니다. 고객님의 트래픽은 여전히 ISP를 통하지만, ISP는 더 이상 트래픽의 최종 목적지를 확인할 수 없습니다. 고객님이 방문하는 웹사이트는 더 이상 고객님의 원래 IP 주소를 볼 수 없으며, 다른 많은 사용자와 공유되며 주기적으로 변경되는 VPN 서버의 IP 주소만 볼 수 있습니다. -출처: Express VPN
4. AWS Direct Connect
전용선을 통해 온프레미스와 VPC 연결
온프레미스
↕ 전용선 (고속, 안정)
AWS 데이터센터
↕
VPC특징:
- 실제 물리 전용선
- 빠르고 안정적
- 인터넷 경유 안함
- 비용이 높음
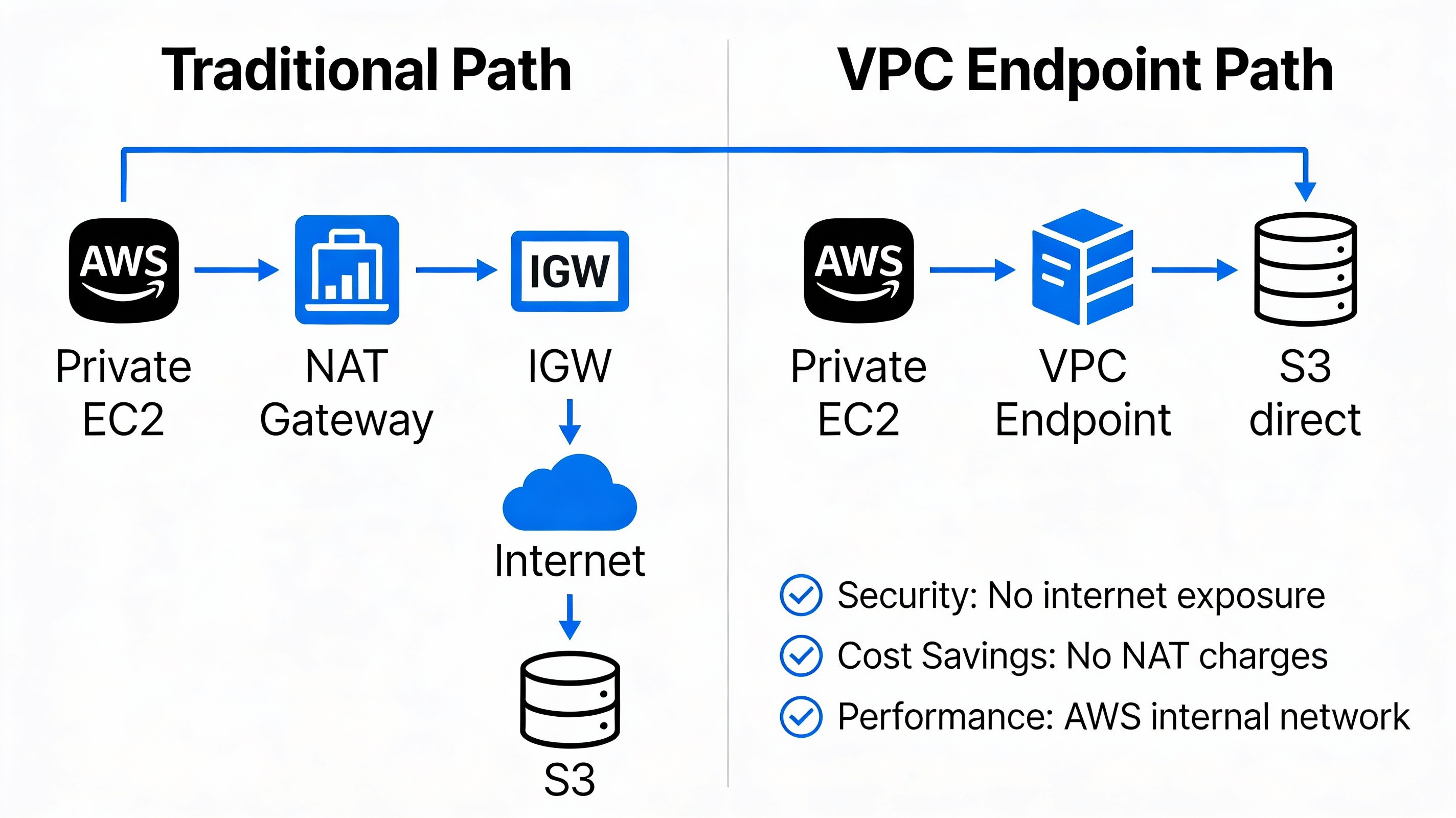
6.11 VPC 엔드포인트 (VPC Endpoint)
VPC 엔드포인트란?
IGW, NAT 없이 Private Subnet에서 AWS 서비스에 접근하는 방법
Private EC2 (NAT/IGW 없음)
↓
VPC 엔드포인트
↓
S3, DynamoDB 등 AWS 서비스장점:
- 인터넷 경유 안함 (보안)
- IGW/NAT 불필요 (비용 절감)
- 빠른 속도 (AWS 내부 통신)
- 간단한 구성
VPC 엔드포인트 종류
- Gateway Endpoint
- S3, DynamoDB만 지원
- 라우팅 테이블에서 설정
- 비용 없음
- Interface Endpoint
- API Gateway, CloudWatch, SNS, SQS 등 대부분 서비스 지원
- ENI (Elastic Network Interface) 생성
- 시간당 비용 발생
사용 예시
상황: Private Subnet의 EC2가 S3에 데이터를 업로드하고 싶음.
기존 방법 (NAT 경유):
EC2 → NAT Gateway → IGW → 인터넷 → S3
VPC 엔드포인트 사용:
EC2 → VPC Endpoint → S3 (AWS 내부 통신)
이점:
- 보안 (인터넷 경유 안함)
- 비용 (NAT 비용 절감)
- 속도 (AWS 내부 통신)
6.12 권장 아키텍처
다층 네트워크 설계
VPC (10.0.0.0/16)
├─ Public Subnet A (10.0.1.0/24) [AZ-a]
│ └─ ELB (로드 밸런서)
│ └─ NAT Gateway (선택사항)
├─ Private Subnet A (10.0.3.0/24) [AZ-a]
│ └─ 웹 서버 (EC2)
├─ Public Subnet C (10.0.2.0/24) [AZ-c]
│ └─ ELB (로드 밸런서)
│ └─ NAT Gateway (선택사항)
└─ Private Subnet C (10.0.4.0/24) [AZ-c]
└─ 데이터베이스 (RDS)설계 원칙
- 다중 가용영역 (Multi-AZ)
- 고가용성 (한 AZ 장애 시 다른 AZ로 자동 전환)
- NAT Gateway 01 (
ap-northeast-2a): EIP52.79.231.1 - NAT Gateway 02 (
ap-northeast-2c): EIP3.35.114.234 - 다만, 비용을 고려하여 설계를 진행해야 됩니다.
- NAT Gateway 01 (
- Public/Private 분리
- Public: ELB, Bastion (관리자 접근용)
- Private: 웹 서버, 데이터베이스
- 계층 분리
- 로드 밸런서 → 웹 서버 → 데이터베이스
- 각 계층마다 보안 그룹 적용
- 네트워크 격리
- 다른 환경(개발/운영)은 별도 VPC
- VPC Peering으로 필요시 연결
6.13 Bastion Host를 통한 Private 접근
Bastion Host란?
Public Subnet에 있는 점프 서버
인터넷 (외부)
↓ SSH
Bastion Host (Public Subnet)
↓ SSH
Private EC2 (Private Subnet)
↓
데이터베이스
용도:
└─ 외부에서 Private 리소스에 접근하기 위한 중간 다리점프서버와 웹 서버의 차이점
- 점프서버는 시스템 관리자가 유지보수를 위해 이용함
- 점프서버는 인터넷에 직접 연결됨
- 웹 서버는 웹 서비스 사용자가 항상 연결을 시도함
- 웹 서버는 로드 밸런서를 통해 간접 연결됨
접근 절차
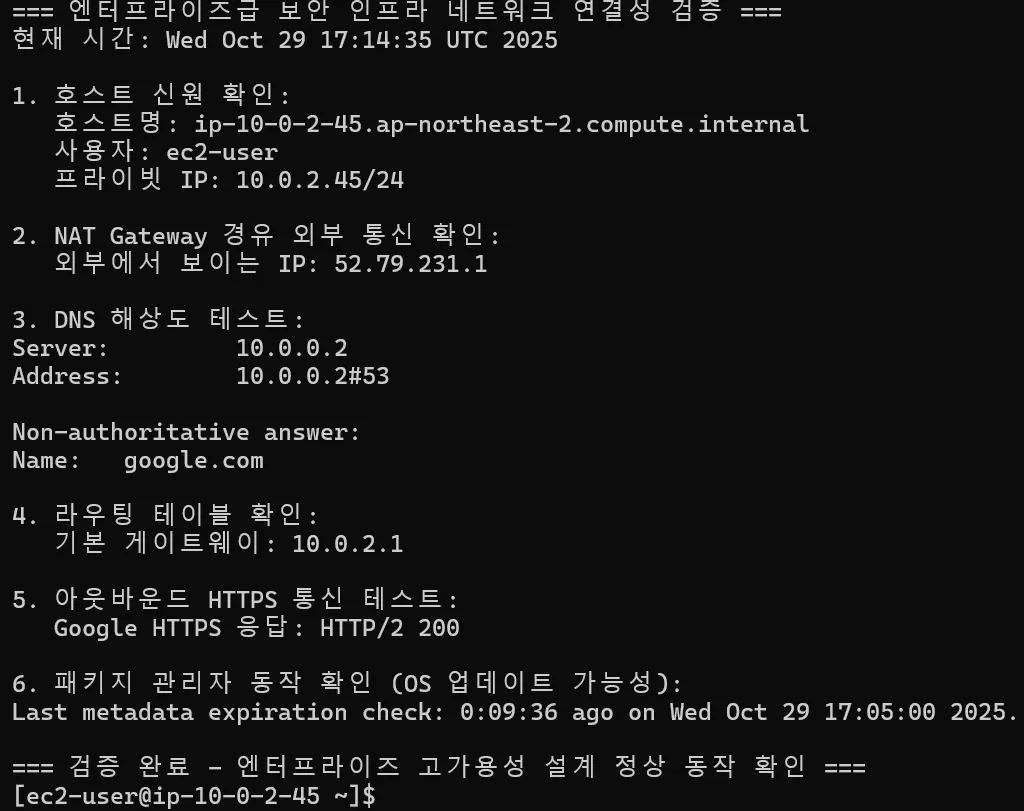
1단계: Bastion Host에 SSH 연결
$ ssh -i bastion_key.pem ec2-user@43.201.57.812단계: Bastion에서 Private EC2 키 파일 다운로드
$ aws s3 cp s3://my-bucket/private_key.pem .3단계: Private EC2에 SSH 연결
$ ssh -i private_key.pem ec2-user@10.0.3.10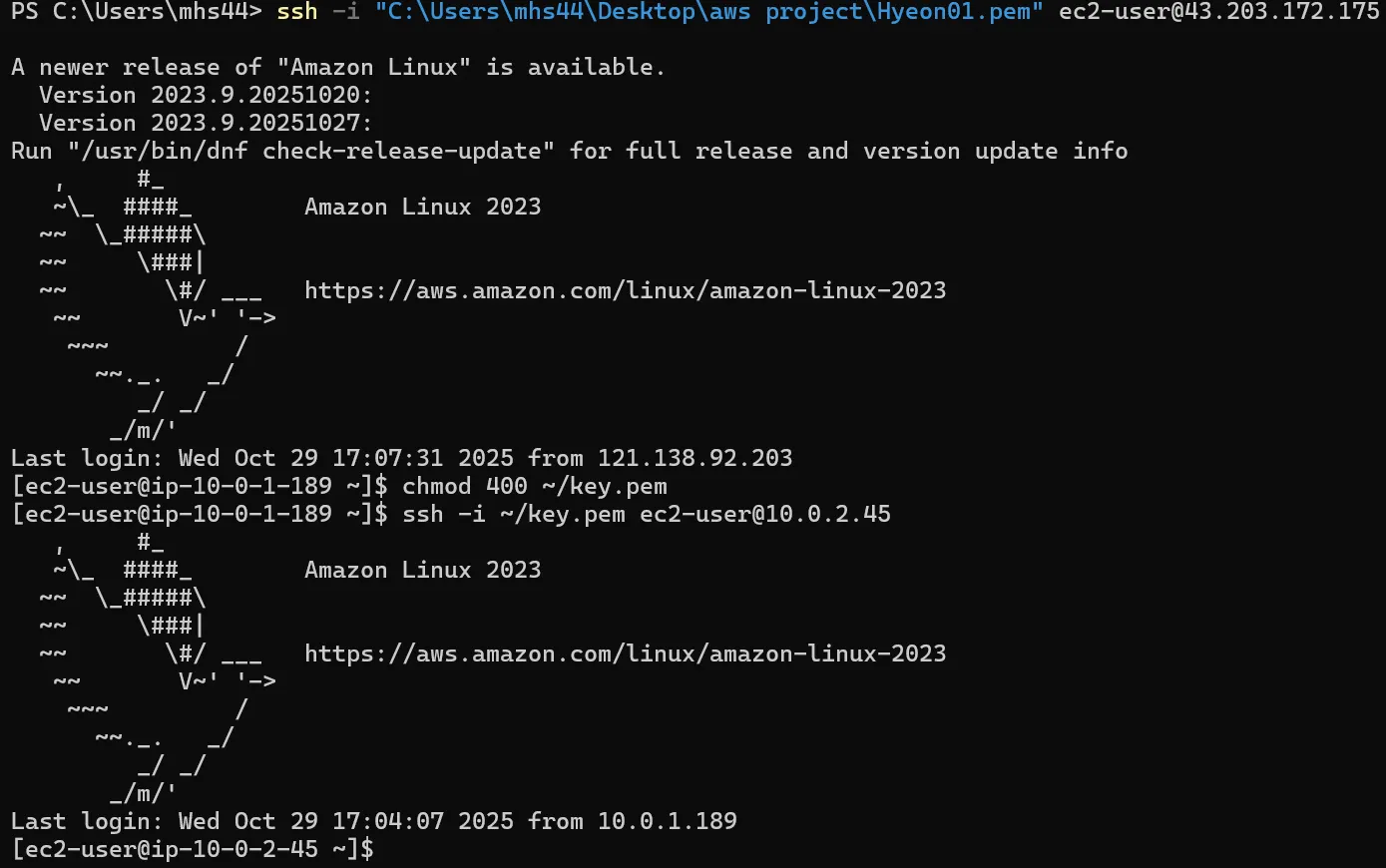 )
)
5. 스토리지 서비스 Amazon S3
5.1 S3 개요
S3란?
S3 (Simple Storage Service)는 AWS의 객체 기반 클라우드 스토리지 서비스입니다.
핵심 특징:
- 객체 기반 저장소: 파일을 "객체"로 저장
- 무제한 확장성: 용량 제한 없음
- 높은 내구성: 99.999999999%
- 다양한 접근: 콘솔, CLI, SDK, 프로그래밍 언어
- 저장 + 전송 요금: 용량과 통신량에 따라 비용 발생
S3의 주요 기능
파일 업로드/다운로드
- GET: S3에서 파일 다운로드
- PUT: S3에 파일 업로드
웹 사이트 호스팅
- 정적 웹사이트를 S3로 직접 서빙
데이터 분석
- Athena, Redshift와 연동
버전 관리
- 파일의 여러 버전 유지
복제
- 다른 리전으로 자동 복제
쿼리 기능
- S3 Select로 데이터 쿼리
5.2 S3의 특징
4가지 핵심 특징
- 확장성
- 다양한 스토리지 클래스
- 수명주기 정책으로 자동 이동
- 용량 걱정 없음
- 가용성·내구성
- 99.999999999% 내구성
- 최소 4개 가용 영역에 자동 복제
- 장애 발생 시에도 서비스 계속 가능
- 신뢰성 (보안)
- 암호화 기능
- 접근 관리 도구
- 각종 규정 준수 (PCI-DSS, HIPAA 등)
- 감사 기능
- 다양한 관리 기능
- 스토리지 클래스 분석
- 수명주기 정책
- 태깅
- 메타데이터 관리
5.3 S3 버킷과 객체
S3의 기본 구조
S3
├─ 버킷 (Bucket)
│ ├─ 객체 (Object) 1
│ ├─ 객체 (Object) 2
│ └─ 객체 (Object) 3
│
└─ 버킷 (Bucket)
├─ 객체 (Object) 1
└─ 객체 (Object) 2규칙:
- 버킷 안에 버킷을 만들 수 없음 (Flat structure)
- 폴더처럼 보이지만 실제로는 prefix일 뿐
버킷 명명 규칙
버킷명 예: atfield.bucket.yang.sample
규칙:
✅ 3글자 이상 63글자 이하
✅ 처음과 마지막은 알파벳이나 숫자
✅ DNS 명명 규칙 준수 (소문자, 숫자, 하이픈만)
❌ 대문자 사용 불가
❌ 언더스코어(_) 사용 불가
❌ IP 주소 형식 사용 불가
❌ 글로벌 고유: 다른 AWS 계정의 버킷명과 중복 불가
URL 형식:
bucketname.s3.regioncode.amazonaws.com/objectname
객체의 구성 요소
객체 = 데이터 + 메타데이터
예:
- 파일명: img01.jpg
- 작성일: 2025년 12월 16일
- 크기: 40KB
- 버전: v2
- 암호화: AES-256
- 태그: Team=DevOps, Env=Prod
5.4 S3 생성 및 사용 절차
S3 사용 순서도
AWS 로그인
- 리전 선택
- S3 대시보드 열기
버킷 생성
- 버킷명 설정 (전역 고유)
- 리전 선택
버킷 설정
- 권한 설정 (퍼블릭/프라이빗)
- 암호화 설정
- 버전관리 활성화
- 웹호스팅 설정 (옵션)
파일 업로드
- 관리 콘솔 또는 프로그래밍으로 업로드
파일 다운로드
- 관리 콘솔 또는 CLI로 다운로드
5.5 버킷 정책과 사용자 정책
접근 권한 제어 방법
S3 접근 제어: 2가지 방법
- 버킷 정책 (Bucket Policy)
- 버킷 단위로 설정
- 누가(Principal), 무엇을(Action), 어디에(Resource) 정의
- JSON 형식
- 예: 모든 사용자에게 특정 버킷 읽기만 허가
2️. 사용자 정책 (User Policy)
- IAM 사용자 단위로 설정
- 사용자가 S3의 어느 버킷에 접근할 수 있는지 정의
- 예: atfield 사용자는 prod-bucket만 접근 가능
버킷 정책 예시 1: 완전 공개
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": "*", // 모든 사용자
"Action": "s3:*", // 모든 작업
"Resource": "arn:aws:s3:::fromis9/*" // fromis9 버킷의 모든 객체
}
]
}버킷 정책 예시 2: 특정 사용자만
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::339713048507:user/atfield" // atfield 사용자만
},
"Action": "s3:*",
"Resource": "arn:aws:s3:::fromis9/img01.jpg" // 특정 파일만
}
]
}정책 구성 요소
┌─ Principal (누가)
│ ├─ "*": 모든 사용자 (익명 접근)
│ ├─ "AWS": AWS 계정 또는 IAM 사용자
│ └─ "Service": AWS 서비스
│
├─ Action (무엇을)
│ ├─ s3:GetObject: 객체 다운로드
│ ├─ s3:PutObject: 객체 업로드
│ ├─ s3:ListBucket: 버킷 목록 조회
│ └─ s3:*: 모든 작업
│
├─ Resource (어디에)
│ ├─ arn:aws:s3:::bucket-name: 버킷
│ └─ arn:aws:s3:::bucket-name/*: 버킷의 모든 객체
│
└─ Effect (결과)
├─ Allow: 허용
└─ Deny: 거부권한 제어 모범 사례
최소 권한 원칙
- 필요한 최소 권한만 부여
퍼블릭 권한 제한
- 필요하지 않으면 익명 접근 차단
정책 검증
- Policy Simulator로 테스트
암호화 활성화
- 서버 측 암호화 (SSE-S3, SSE-KMS)
버전 관리
- 실수로 인한 삭제 방지
복제
- 다른 리전에 백업 유지
5.6 S3 요금
S3 요금 체계
S3 요금 = 저장 비용 + 전송 비용
┌─ 저장 비용 (Storage)
│ ├─ 저장한 데이터 용량
│ └─ 월별로 과금 (GB당)
│
└─ 전송 비용 (Data Transfer)
├─ 업로드: 일반적으로 무료
├─ 다운로드: 다운로드한 용량에 따라 과금
└─ 리전 간 전송: 비용 발생비용 최적화 전략
스토리지 클래스 선택
- 자주 접근하지 않는 데이터는 저렴한 클래스 사용
수명주기 정책
- 오래된 데이터 자동으로 저렴한 클래스로 이동
- CloudFront 활용
- 자주 접근하는 데이터는 캐시하여 전송비 절감
- 정기적 검토
- 불필요한 데이터 정기적으로 삭제
5.7 스토리지 클래스 및 수명주기
S3 스토리지 클래스
S3 스토리지 클래스: 4가지
- Standard (표준)
- 내구성: 99.999999999%
- 가용성: 99.99%
- 사용 시기: 자주 접근하는 데이터
- 비용: 가장 비쌈 (저장비용 높음)
- Standard-Infrequent Access (표준 IA)
- 내구성: 99.999999999%
- 가용성: 99.9%
- 사용 시기: 가끔 접근하는 데이터 (월 1-2회)
- 최소 보관 기간: 30일
- 비용: 저장비용 저렴, 조회비용 발생
- Glacier (글래시어)
- 내구성: 99.999999999%
- 가용성: 99.99%
- 사용 시기: 아카이브, 장기 백업 (복원 시간 필요)
- 최소 보관 기간: 90일
- 복원 시간: 몇 분~12시간
- 비용: 가장 저렴
- Deep Archive (딥 아카이브)
- 내구성: 99.999999999%
- 가용성: 99.99%
- 사용 시기: 규정상 장기 보존 (7년, 10년)
- 최소 보관 기간: 180일
- 복원 시간: 12시간~48시간
- 비용: 극저렴
스토리지 클래스 선택 기준
접근 빈도를 기준으로:
자주 접근 (매일)
↓
Standard (표준) ← 가장 빠름, 가장 비쌈
가끔 접근 (월 1-2회)
↓
Standard-IA (표준 IA) ← 저장비용 낮음, 조회비용 있음
드물게 접근 (연 몇 회)
↓
Glacier (글래시어) ← 매우 저렴, 복원에 시간
보관만 함 (규정상)
↓
Deep Archive (딥 아카이브) ← 극저렴, 오래 기다려야 함
수명주기 정책 (Lifecycle Policy)
수명주기 정책 = 객체의 자동 이동 규칙
예시: 이미지 파일 관리 정책
객체 생성
↓ (30일 경과)
Standard에서 Standard-IA로 이동 (저장비용 절감)
↓ (90일 경과)
Standard-IA에서 Glacier로 이동 (거의 접근 안 함)
↓ (365일 경과)
Glacier에서 Deep Archive로 이동 (연간 보관)
↓ (1825일 경과)
객체 삭제 (규정 보관 기간 만료)
정책 설정:
- 전환 규칙 (Transition)
- 일정 기간 후 다른 클래스로 자동 이동
- 만료 규칙 (Expiration)
- 일정 기간 후 자동 삭제
5.8 S3 웹사이트 호스팅
정적 웹사이트 호스팅
S3를 웹 서버로 사용
기존 웹 서버 (EC2):
사용자 → EC2 인스턴스 → HTML, CSS, JS 반환
S3 웹 호스팅:
사용자 → S3 버킷 → 정적 파일 (HTML, CSS, JS) 반환
특징:
장점:
- 서버 관리 불필요
- 자동 확장
- 낮은 비용
- 높은 가용성
제약:
- 정적 콘텐츠만 가능 (동적 처리 불가)
- PHP와 같은 서버 사이드 언어는 직접 실행할 수 없다.
- 데이터베이스 쿼리 불가
S3 웹호스팅 설정
단계 1: 버킷 생성
- 버킷명 = 도메인명 (예: example.com)
단계 2: 파일 업로드
- index.html (메인 페이지)
- style.css, script.js 등
단계 3: 정적 웹사이트 호스팅 활성화
- 속성 -> Static website hosting -> Enable
단계 4: 인덱스 문서 설정
- Index document: index.html
- Error document: error.html (옵션)
단계 5: 버킷 정책으로 공개
- Principal: "*"
- Action: s3:GetObject
- Resource: arn:aws:s3:::bucket-name/*
단계 6: URL로 접속
5.9 S3 버전 관리
버전 관리란?
파일을 여러 버전으로 관리하는 기능
예: 대충 중요한 내용.pdf 파일
버전 관리 없음:
최신 버전
↓ (실수로 삭제)
파일 없음 ❌-> 망했음
버전 관리 있음:
버전 2 (최신)
버전 1 (이전)
버전 0 (원본)
↓ (버전 2 삭제)
버전 1 복원 ✅ (복구 가능)->살았음
버전 관리 활성화 및 복원
설정:
- S3 버킷 선택
- 속성 > 버킷 버전 관리 > Enable
- 저장
객체 삭제 시 작동 방식:
- 실제로 삭제되지 않음
- "삭제 마커(Delete Marker)"가 생성됨
- 이전 버전은 여전히 존재
복원 방법:
- S3 버킷에서 "버전 표시" 활성화
- 삭제된 파일 우클릭
- "삭제 마커 제거" 선택
- 이전 버전 선택하여 복원
버전 관리 사용 시나리오
시나리오: 중요한 문서 관리
Day 1: 대충 중요한 내용.pdf (v1) 업로드
Day 5: 대충 중요한 내용.pdf (v2) 업로드 (내용 수정)
Day 10: 대충 중요한 내용.pdf (v3) 업로드 (다시 수정)
만약 Day 10의 v3에 오류가 있다면?
→ 버전 관리로 Day 5의 v2로 즉시 복원 가능
감사:
- 누가, 언제, 어떤 버전을 만들었는지 추적 가능
- CloudTrail 로그로 기록됨
5.10 S3 복제 (Replication)
복제의 필요성
복제 = 한 버킷의 객체를 다른 버킷(다른 리전)으로 자동 복사
사용 사례:
재해 복구 (Disaster Recovery)
- 서울 리전 S3 → 도쿄 리전 S3 (자동 복제)
- 서울 데이터센터 장애 시 도쿄에서 서비스 계속
규정 준수 (Compliance)
- 해외 데이터 거주 요건이 있는 경우
- 여러 지역에 데이터 유지
성능 최적화
- 사용자 위치에 가까운 데이터 복사본 유지
- 지연시간 감소
데이터 마이그레이션
- 한 계정에서 다른 계정으로 안전하게 이동
복제 설정
전제 조건:
- 원본 버킷 버전 관리 활성화
- 대상 버킷 버전 관리 활성화
- IAM 권한 설정
설정 단계:
- 원본 버킷 선택
- 관리 > 복제 규칙 > 복제 규칙 생성
- 대상 버킷 선택 (다른 리전)
- IAM 역할 선택
- 규칙 활성화
동작:
- 자동으로 새 객체 복제
- 객체 삭제도 복제됨 (동기화)
- 기존 객체는 복제되지 않음 (배치 연산으로 별도 처리)
5.11 S3 데이터 분석
S3와 분석 서비스 연계
S3 데이터 분석 파이프라인
┌─ 원본 데이터 저장
│ └─ S3 Standard (자주 사용)
│
├─ 데이터 쿼리 및 분석
│ ├─ S3 Select: 파일의 일부만 선택
│ ├─ Amazon Athena: SQL로 S3 쿼리
│ └─ Amazon Redshift: 대용량 데이터 분석
│
├─ 결과 저장
│ └─ S3 (분석 결과)
│
└─ 시각화
└─ QuickSight: 대시보드 생성각 도구의 역할
- S3 Select
- CSV, JSON 파일에서 특정 컬럼만 가져오기
- SELECT * FROM s3object WHERE age > 30
- 비용 절감 (전체 파일 다운로드 불필요)
- Amazon Athena
- S3의 데이터를 직접 SQL로 쿼리
- 서버 관리 불필요
- 쿼리한 데이터량에 따라 비용
- Amazon Redshift
- 대용량 데이터 웨어하우스
- S3의 데이터를 로드하여 분석
- OLAP(온라인 분석 처리)에 최적
- Amazon QuickSight
- BI(비즈니스 인텔리전스) 도구
- Athena, Redshift 결과를 시각화
- 대시보드, 보고서 생성
5.12 CloudFront (콘텐츠 전송 네트워크)
CloudFront란?
CloudFront = CDN (Content Delivery Network)
Vercel이나 Railway 같은 거임.
역할:
S3의 데이터를 전 세계 엣지 로케이션에 캐시
└─ 사용자와 가까운 서버에서 빠르게 제공
이점:
속도 향상: 지연시간 감소
비용 절감: S3 대역폭 비용 감소
보안: DDoS 방어
글로벌 배포: 자동으로 전 세계 배포
CloudFront 동작 방식
처음 요청:
사용자 → CloudFront → S3에서 데이터 가져오기 → 캐시 저장
다음 요청:
사용자 → CloudFront (캐시된 데이터 반환) ← S3 접근 안 함
이점:
- S3 접근량 감소 → 비용 절감
- 사용자에게 더 빠른 응답
5.13 S3 보안 고려사항
S3 데이터 보호
- 암호화 (Encryption)
- 전송 중: HTTPS/TLS
- 저장 시: SSE-S3, SSE-KMS
- 접근 제어 (Access Control)
- 버킷 정책
- IAM 정책
- ACL (레거시)
3.모니터링 (Monitoring)
- S3 액세스 로그
- CloudTrail
- 버전 관리
- 실수 방지
- 복제
- 재해 복구
권장 보안 설정
✅ 퍼블릭 액세스 차단
- 필요하지 않으면 익명 접근 비활성화
✅ MFA Delete 활성화
- 삭제 전 다중 인증 필수
✅ 서버 측 암호화
- SSE-KMS 권장 (더 강력)
✅ 로깅 활성화
- S3 액세스 로그 기록
✅ 정기적 감사
- CloudTrail로 모든 변경 추적
✅ 객체 잠금
- WORM(Write Once Read Many)
- 한번 쓰면 수정/삭제 불가
S3 vs EC2 스토리지 비교
| 항목 | S3 | EC2 (EBS) |
|---|---|---|
| 유형 | 객체 기반 | 블록 기반 |
| 용도 | 파일 저장 | 시스템 디스크 |
| 접근 | HTTP API | 블록 디바이스 |
| 버전 관리 | 지원 | 스냅샷만 |
| 확장성 | 무제한 | 볼륨 크기만큼 |
| 비용 | 저장 + 전송 | 용량 기반 |
실습하는 입장에서 요금이나 비용은 굳이 상관쓰지 않아도 상관없다. 물론 프리티어라는 가정에서...
아직까진 솔직히 이론적인 내용이라 그다지 어려울 것도 없다.
나중에 진짜 디플로이 할 때 이것저것 람다랑 섞어서 쓰는 거랑 장애 발생할 때 장애발생지점 찾는게 리얼 개헬인데.... 그거에 비하면 이건 개망고라고 볼 수 있다.
'SK Shieldus Rookies 29' 카테고리의 다른 글
| [SK shieldus Rookies 29기] 31일차 (0) | 2026.01.14 |
|---|---|
| [SK shieldus Rookies 29기] 30일차 (1) | 2026.01.14 |
| [SK shieldus Rookies 29기] 28일차 (0) | 2026.01.14 |
| [SK shieldus Rookies 29기] 27일차 (1) | 2025.12.15 |
| [SK shieldus Rookies 29기] 26일차 (0) | 2025.12.15 |



